Chapter 10: Advanced Memory Management
10.1 Zero-Copy I/O
How should the kernel transfer hardware device data to userspace application? A traditional approach would be for the device to copy data (e.g. from disk) into a kernel buffer, and then for the kernel to copy it from the buffer to userspace. Is there a way to avoid this level of indirection though, i.e. have the hardware device transfer data directly to the userspace application? In other words, can we achieve zero-copy I/O.
Moving all userspace applications into the kernel is obviously terrible for security reasons. Allowing applications to directly manipulate a kernel buffer via syscalls is a better idea, but it's not applicable to situations where the application may need to perform more complex work with the data.
There are, in fact, two popular, performant solutions for zero-copy I/O, that eliminate the copy across the kernel-user boundary for large blocks of data (for small blocks, it doesn't impact performance significantly).
Page Table Swap
- User-to-kernel space copy:
- Kernel changes PTE to read-only
- Kernel pins page to prevent eviction from main memory
- Kernel then copies the userspace memory directly to the device
- Kernel-to-user space copy:
- PTE initially points to empty user buffer
- Kernel swaps PTE to point to full kernel buffer when data is ready
Virtual DMA
Modern hardware I/O devices have been granted the ability to transfer data to/from virtual addresses, not just physical addresses. Thus, the kernel can simply provide the virtual address of the user-level buffer to the hardware device, for it to copy to/from.
10.2 Virtual Machines
VM Page Tables
Virtual machines essentially have two sets of page tables!
- GVA to GPA (Guest Virtual Address to Guest Physical Address)
- GPA to HPA (Guest Physical Address to Host Physical Address)
The above configuration exists because the OS running inside the VM think it is translating to (and has access to) physical memory, when in reality it's an illusion provided behind the VM manager and host OS. Why? Because this VM is itself a user process, and must not be granted actual access to physical memory. Otherwise, the guest OS could take over the host OS! Thus, a GPA is effectively just a HVA (Host Virtual Address).
But, translating from GVA to GPA, and then GPA to HPA, would be slow on hardware that supports only one page table walk for address translation! Each memory access would require the hypervisor (VM manager) to manually emulate the page table walk. As aforementioned, this is much, much slower than a hardware page table walk.
There are two well-known solutions to this problem: shadow page tables, a legacy, software-assisted method and extended page tables, a modern, hardware-supported method.
Shadow Page Tables
Shadow page tables are essentially direct mappings from GVA to HPA. In essence, this is the page table that the hardware actually walks for address translation (e.g. in x86 the CR3 register is set to the shadow page table corresponding to a guest virtual address space/guest page table). So, a guest memory access doesn't have to trap into the hypervisor, but rather can directly use the MMU and let the hardware perform the page table walk for address translation.
Notably, the guest OS is unaware of the shadow page table. In its eyes, it's still managing the address translations and accesses for its or its process's page table. Thus, it's necessary to keep the shadow page table updated when the guest OS updates the its page table, i.e. the GVA to GPA page table.
In particular, if the guest OS updates a PTE in the guest page table (i.e. GVA now maps to a different GPA, which maps to a different HPA in the host page table), this update must trap into the hypervisor so that it can update the shadow page table mapping for this GVA to point to the new HPA. This is typically done by setting the pages containing the guest page tables as read-only in the host page table. (To clarify, each guest page table lives at some GPA, which is equivalent to an HVA. The PTE for the HVA in the host page table is marked read-only, to allow trapping into the host OS / hypervisor upon modification).
It's also necessary to update the shadow table if the GPA to HPA mapping changes, i.e. the host page table of the hypervisor / backing the VM's address space.
However, there's one glaring issue with shadow page tables—maintaining coherence/consistency with the guest page tables is still slow, as each update requires a trap into the hypervisor, i.e. a VM exit. Each of these exits is very expensive (due to the context switch + associated TLB flush), and considering that OS's frequently update page tables or context switch (after all, the guest OS thinks it's directly modifying physical memory, which is fast).
Thus, we turn to the modern, hardware-assisted solution: extended paging.
Extended Page Tables (EPT)
Extended Page Tables, also known as Second-Level Address Translation or even Nested Page Tables (AMD), is essentially an augmentation of the hardware MMU, in which it is provided the ability to perform a two-level address translation walk, i.e. GVA to GPA to HPA. In essence, we introduce another MMU, the EPT MMU, which will translate GVA to GPA using the guest page table, while the typical MMU continues to translate GPA to HPA.
It's not quite as simple as it seems though—while a typical (i.e. host process) memory access on x86-64 (assuming the default 5-level paging) requires only 5 memory accesses (HVA to HPA), a guest process memory access requires 25 memory accesses (GVA to HPA)! Why is this the case?
The following diagram succinctly illuminates the general idea.
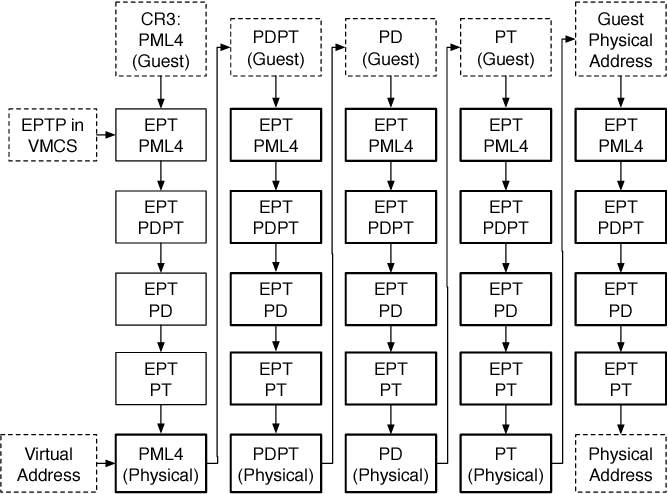
What's going on here??
Well, consider that the EPT MMU must walk the guest page table. But, the guest page table itself stores GVA to GPA mappings, and the EPT MMU cannot just directly access a memory address by GPA—that a virtual address for the host! Thus, each time the EPT MMU retrieves the GPA of the next level of the guest page table, it must translate this GPA to an HPA—in other words, the regular MMU has to walk the host page table for every step of the guest page table walk. Thus, on x86-64, memory accesses are required.
This is certainly slower than memory accesses on the host, but remains much faster than shadow page tables. EPT takes at most cycles of a regular memory access (or, for an -level page table), but a shadow page table takes several orders of magnitude more cycles. Thus, practically all modern machines have EPT enabled to keep VMs performant.
Paravirtualization
Finally, there is actually one solution that I didn't mention before, because it isn't quite the same. Paravirtualization is a methodology where the guest OS is specifically an OS that is aware it is operating in a VM. This is known as an enlightened OS, and are frequently much more performant than using a normal OS in a VM. However, it's not widely used because the guest OS must be entirely reimplemented to be enlightened, a highly non-trivial task.
Transparent Memory Compression
Consider the following situation: a host machine has 2 VMs running, both with their guest OS of the same version of Ubuntu. Then, would the host machine have to create separate pages for the distinct executable kernel images, despite the memory being the exact same.
The solution is deduplication, in which the hypervisor maps these executable images to the same physical pages in main memory, in order to avoid keeping the same exact data twice in memory. In fact, the hypervisor does this for all more than just the kernel images—periodically, a scavenger runs in the background to identify VM pages that can be deduplicated, and modifies the guest page table such that these addresses point to the same GPA (effectively sharing the same host physical page).
There are actually two different cases to consider, though, for memory deduplication.
- Multiple copies of the same page. This is precisely the design described above—these guests' PTEs point to the same page, with the same content. This can be used for read-only pages, or read-write pages via copy-on-write. This is especially useful for kernel images, shared libraries, and zeroed pages.
- Compression of unused pages. There also exist memory deduplication strategies for a VM's pages that are close, but not quite the same, as a another VM's pages. In particular, for a fairly infrequently used page that is a delta of (close to) an existing page in another VM, the OS can, instead of evicting the page, can replace the page with a delta that indicates the difference between the similar pages. Then, it can mark the full page that's kept (not replaced with a delta) as read-only, and mark the delta as invalid. Then, any access to the delta can quickly regenerate the page using the full page already in main memory + the difference, while any write to the full page will either update (re-compress) the delta or evict it.
10.3 Fault Tolerance
Checkpoint and Restart
A simple approach to fault tolerance is to have the OS periodically save the process's state to disk, to allow restoring the process state from this checkpoint or snapshot if the process crashes. This involves first suspending each thread, saving each thread's registers to memory, and then copying the process's memory to disk.
Note that we must pause the threads when saving its memory; otherwise, we'll have a race condition in which different portions of the state are in different sections of the program. However, we can optimize this a bit to minimize process stalling—we can mark the process's pages as COW, and then reset each to read-only once copying to disk is finished.
This is also helpful for process migration, i.e. moving a running program from one machine to another. This is commonly used to load balance VMs across machines in a datacenter.
Recoverable Virtual Memory
Checkpoints are expensive, though. Can we do better in saving virtual memory?
A naive solution is to log changes, rather than saving the entirety of virtual memory. However, this would require trapping on every write to main memory—a prohibitively expensive operation. We can do something similar, though, at the page granularity. Every time the system takes a snapshot, only the pages that have been modified are saved to disk. These are called incremental checkpoint.
Deterministic Debugging
Debugging a sequential program is easy. Debugging a parallel program is harder, due to non-determinism. Debugging an operating system is even harder, not only due to extensive concurrency but also a result of the difficulty in differentiating what's "input" and "output."
Virtual machines, though, provide a nice abstraction for a deterministic debugging environment of an operating system (and thus, by extension, concurrent programs). Essentially, the hypervisor records every action taken by the guest operating system, and then replays the precise actions. We can also record the exact timing of interrupts to simulate these exactly too!
10.4 Security
TL;DR: we can use VMs as honeypots and use it for defense in depth, since taking over the host OS from a VM requires a privilege escalation followed by a VM escape followed by another privilege escalation.
10.5 User-Level Memory Management
The key idea of this section is that applications may have better visibility into how to manage its own pages, i.e. which pages to evict, page access control, etc. Thus, some operating systems provide some user-level control over memory, commonly in the following two forms:
- Pinned pages. Programs can pin virtual memory pages to physical pages, preventing eviction unless absolutely necessary.
- User-level pages. On a page fault/protection violation, the kernel fault handler will allow the application to manage the fault. (Note: the user-level page handler must be stored in pinned memory, to avoid infinite recursion).