Chapter 4: Concurrency and Threads
4.1 Why Threads?
- Program Structure: logically concurrent tasks
Programs that interact with the real world frequently have concurrent activities to perform.
- Responsiveness: shifting work to run in the background
For interactive computers, threads help improve responsiveness and perceived performance for the user by creating threads to perform work in the background while allowing the user to still do other things with the program/computer. For the OS, this is critical to ensure that the computer remains responsive while expensive operations (like disk writes) are happening.
- Performance: exploiting multiple processors
As hardware continuously improves and more and more cores are embedded into a single computer, utilizing multiple CPUs of a computer has become critical to improving performance. Threads are a way to split work between different processors.
- Performance: managing I/O devices
While expensive I/O device operations are happening, it's more useful for the operating system to perform other tasks in the meantime. By creating a separate thread for I/O operations, the kernel can effectively multitask, using processor power for other processes while waiting on I/O operations. It also allows the kernel to respond to sudden, external events like key presses while still working on other tasks.
4.2 Thread Abstraction
A thread is a single execution sequence that represents a separately schedulable task.
- Single Execution Sequence: Simply put, each thread executes a sequence of instructions, as in a normal process.
- Separately Schedulable Task: An OS can run, suspend, or resume a thread at any time.
In the thread abstraction, the applications are provided with the illusion of an infinite number of processes. This is, of course, untrue. But the OS is able to implement this via a thread scheduler, allocating time slices for each thread to be able to use a processor. A consequence of this design, though, is that the thread abstraction paints threads as running on a dedicated virtual processor with unpredictable, variable speed.
Cooperative vs. Preemptive Multithreading
Cooperative multithreading is a system in which a thread runs until it voluntarily relinquishes control of the processor. These systems were used as recently as the early 2000s, but are no longer a part of modern operating systems. (A malicious application could easily abuse this to hog the processor!). The idea remains in use on the application level, though.Preemptive multithreading is a system in which the processor has full control over which thread is running, able to arbitrarily switch from one thread to another at any given time. This is used in the vast majority of modern operating systems.
4.3 POSIX Thread API
The important functions in the POSIX Thread (pthread) API can be found in the pthread.h header and are as follows:
/*
The pthread_create() function starts a new thread in the calling
process. The new thread starts execution by invoking
start_routine(); arg is passed as the sole argument of
start_routine().
*/
int pthread_create(pthread_t *restrict thread, const pthread_attr_t *restrict attr, typeof(void *(void *)) *start_routine, void *restrict arg);
/*
pthread_yield() causes the calling thread to relinquish the CPU.
The thread is placed at the end of the run queue for its static
priority and another thread is scheduled to run.
*/
int pthread_yield(void); // deprecated
/*
The pthread_join() function waits for the thread specified by
thread to terminate. If that thread has already terminated, then
pthread_join() returns immediately. The thread specified by
thread must be joinable.
If retval is not NULL, then pthread_join() copies the exit status
of the target thread (i.e., the value that the target thread
supplied to pthread_exit(3)) into the location pointed to by
retval. If the target thread was canceled, then PTHREAD_CANCELED
is placed in the location pointed to by retval.
If multiple threads simultaneously try to join with the same
thread, the results are undefined. If the thread calling
pthread_join() is canceled, then the target thread will remain
joinable (i.e., it will not be detached)
*/
int pthread_join(pthread_t thread, void **retval)
/*
The pthread_exit() function terminates the calling thread and
returns a value via retval that (if the thread is joinable) is
available to another thread in the same process that calls
pthread_join(3).
Any clean-up handlers established by pthread_cleanup_push(3) that
have not yet been popped, are popped (in the reverse of the order
in which they were pushed) and executed. If the thread has any
thread-specific data, then, after the clean-up handlers have been
executed, the corresponding destructor functions are called, in an
unspecified order.
When a thread terminates, process-shared resources (e.g., mutexes,
condition variables, semaphores, and file descriptors) are not
released, and functions registered using atexit(3) are not called.
After the last thread in a process terminates, the process
terminates as by calling exit(3) with an exit status of zero;
thus, process-shared resources are released and functions
registered using atexit(3) are called
*/
void pthread_exit(void *retval) // noreturn
Fork-Join Parallelism is a very common method of multithreading, in which a parent thread forks several child threads to perform work, before joining (waiting for) all their results. Each thread executes independently and deterministically. With the pthread API, this is done via
pthread_createandpthread_join.
4.4 Thread Data Structures and Life Cycle
Every thread has some per-thread state and metadata associated with it that the processor must save and restore when switching between threads. These are stored in what is commonly known as the Thread Control Block (TCB). For ELF files (Linux), this is typically called thread local storage.
The TCB holds two types of per-thread information:
- Computation State: This is primarily a pointer to the thread's stack and a copy of the processor registers. These are saved and restored for the processor's use whenever switching threads.
- Metadata: Thread ID, scheduling priority, status, etc.
Aside: Stack Size
One interesting problem is how much stack space should be allocated for each thread. For kernel threads, since they operate directly on physical memory, they are typically quite minimal. For Linux running on Intel x86, the default is 8 KB, and the kernel takes extra precautions to ensure a thread does not overflow its stack.Meanwhile, for userspace threads, the kernel can provide the illusion of infinite memory via virtualization. Thus, these stacks can grow without bound. However, large or extremely rapid increases in size are generally caught by the operating system, since this typically indicates unbounded recursion or other unintended behavior.
Threads do still share some state between threads running in the same process or within the operating system kernel. Most prominently, program code, statically allocated global variables, and heap variables are typically shared between threads. Note that some of these can become thread-local, e.g. heap arenas are frequently thread-specific for performance reasons (better cache locality).
4.5 Thread Life Cycle
The thread life cycle can be summarized in the below diagram:
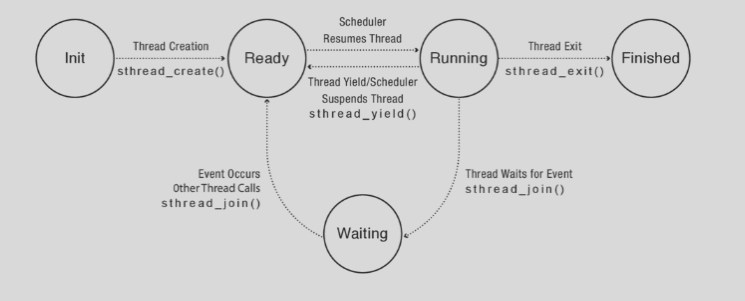
-
INIT: Thread creation moves a thread into the INIT state and initializes any per-thread data structures. Once finished,
pthread_createwill add the thread to the ready list, the set of runnable threads waiting for a processor.Sidenote: the list of runnable threads is not actually a list. In Linux, for example, it is a red-black tree balanced by priority.
-
READY: A thread in the READY state is available to run and waiting for a processor. Its TCB is on the ready list, with the saved computational state. At The scheduler can bring a READY thread to the RUNNING state at any time.
-
RUNNING: A thread in the RUNNING state is currently running. To move to the READY state, one of two things can happen:
- The scheduler preempts the RUNNING thread and moves it to the READY state after saving its current state and switching the processor to another READY thread.
- The RUNNING voluntarily relinquishes the processor (
pthread_yield)
-
WAITING: A thread in the WAITING state is waiting for an event, possibly I/O or something else. It is not running on the processor during this time, to allow other applications to run. The TCB is stored on the waiting list of some synchronization variable associated with the event. This could be caused by a function like
pthread_join.
-
FINISHED: A thread in the FINISHED state is done, and will never run again. The state is not immediately freed yet, in order to let functions like
thread_exitpass its exit value to its parent thread if necessary. Its TCB is on the finished list, and the space will eventually be reclaimed once its data is no longer needed.
4.6 Kernel Threads
We first consider the simplest case: the implementation of threads that run inside the operating system with full privileges.
Thread Creation
- Allocate per-thread state. This generally involves allocating space for the TCB and the kernel stack (recall that this is fixed size in the kernel).
- Initialize per-thread state. First, the constructor initializes the thread's registers. It then starts the thread in a dummy "stub" function that will call
start_routine(arg). This extra step is necessary in case thestart_routinefunction never callsthread_exit. In this case, it would return to whatever is at the top of the stack. In the stub function, the kernel ensures thatthread_exitis called. - Put TCB on ready list. INIT READY.
Thread Deletion
- Put TCB on finished list. RUNNING/READY FINISHED.
- Free per-thread state. Importantly, a thread should not be deallocating its own state. This could lead to issues (e.g. interrupt during freeing leads to memory leak, context switch code tries to write to deallocated memory, etc.). It is always necessary for another thread to free this thread's state.
Thread Context Switch
There are two types of thread context switches: voluntary and involuntary. Voluntary switches are triggered by functions like pthread_yield, and proceed as follows:
- Turn off interrupts. This prevents the kernel from attempting to perform two context switches at the same time.
- Save per-thread state.
- Switch to next thread on ready list. The next thread to run is chosen by the scheduler.
Meanwhile, an involuntary context switch might occur due to an interrupt, processor exception, or trap.
- Save per-thread state. Hardware saves some state upon interrupt/exception, and software saves the rest of the state when the handler runs.
- Run handler. No need to switch from user mode to kernel mode, since a kernel thread was interrupted.
- Switch to next thread on ready list. In contrast to what you might expect, the kernel will then switch to the next thread on the ready list, rather than always resuming the thread that was just suspended.
4.7 Kernel Threads and Single-Threaded User Processes
Since each process can have multiple threads (note: on Linux, this is not true; threads are simply lightweight processes), each user process needs a Processor Control Block (PCB) that contains process metadata. Each thread, meanwhile, must have its own interrupt stack too.
Note one important difference between context switching from a kernel thread to a handler and doing the same for a user thread. If the processor is already in kernel mode, it simply pushes the instruction pointer and eflags onto the existing stack. This is because kernel threads don't have interrupt stacks, as their stack functions fine for this. Meanwhile, context switching from a user thread requires the hardware to change the stack pointer to the interrupt stack, and then push the instruction pointer, eflags, and original stack pointer onto the stack. This means that the iret instruction will also function differently, depending on the contents of the saved eflags. That is, after popping the saved eflags, it'll check the mode to see if it needs to pop the stack pointer too.
4.8 Multithreaded Processes
Each thread must have
- A userspace stack
- A kernel interrupt stack for traps, processor exceptions, and interrupts
- A kernel TCB
Though, there do exist non-operating-system threading applications. Some userspace threading libraries exist. For instance, the earliest implementations of Sun's Java Virtual Machine used green threads. The idea is essentially the same, except all the normal process and thread management data structures are allocated in the process's address space rather than the operating system. The only issue with green threads, though, is that the OS remains unaware of the state of the userspace ready list. So, if an application blocks to wait for I/O, the kernel doesn't know to switch to another userspace thread.
Most operating systems do allow preemption among userspace threads executing within a process. This functionality is delivered through upcalls, or signals on UNIX systems. Frequently, userspace thread implementations will register timer signal handlers to context switch between threads periodically.
Modern operating systems, though, have built-in kernel support for userspace threads. For instance, thread_join is frequently made hybrid, in which thread_join doesn't always have to make a syscall, and should recognize when a thread has exited from data structures in the process. On a multiprocessor, it may even be more efficient to let thread_join block for a few microseconds in hopes the other thread will finish during this time.
Multiprocessors may also implemented per-processor kernel threads. This allows a userspace library to multiplex userspace threads on top of kernel threads while kernel threads are multiplexed on top of physical processors. This allows running the user-level scheduler in parallel across all kernel threads.
Recent developments have also led to scheduler activations. Essentially, the userspace thread scheduler is notified (activated) of every kernel event that potentially affects the userspace thread system. These events include
- Changing the number of virtual processors
- Transitions between thread states (e.g. waiting for I/O)
Alternative Abstractions
Asynchronous I/O and Event-Driven Programming
In async I/O, a single-thread process will make multiple concurrent I/O requests simultaneously. The operating system will provide the result later, asynchronously, by calling a signal handler, placing the result in a queue in process memory, or storing the result in kernel memory until the process makes a syscall (polls).
Asynchronous I/O has given rise to event-driven programming where a thread spins in a loop, with each iteration processing a different I/O event.
Data Parallel Programming
Data parallel programming is simply executing a single operation on multiple pieces of data simultaneously. Most commonly, SIMD (single instruction multiple data), or more recently MIMD (multiple instruction multiple data). GPUs are especially powerful for these types of tasks.