2. Divide and Conquer
Divide and Conquer...
- Breaks a problem into subproblems which are the same problem but smaller
- Recursing through the subproblems and subsequently combining their answers
2.1 Multiplication
The product of two complex numbers can be reduced to 3 multiplications instead of the usual 4. (Gauss)
This small constant factor improvement seems negligible; however, when applied at every step in a recursion, it has a noticeable impact on time complexity.
We can apply the same concept to integer multiplication. Let be two -bit integers, and, for convenience, let . We now split into two chunks of equal bit length:
And, following Gauss's idea, expand and simplify the multiplication:
Note that we only have to perform 3 multiplications:
Let represent the overall running time of the multiplication algorithm, provided an -bit input. Expression then has a recurrence relation of
since each multiplication () should take , since its an -bit multiplication, and both summing -bit numbers and left-shifting (the coefficients) are linear operations in .
Deriving the explicit form of this recurrence relation results in , which provides no improvement over the standard multiplication method taught in school.
In contrast, expression has the recurrence relation of
since it has 3 multiplications, and the rest of the operations are still linear in , as previously stated.
Deriving the explicit form of this recurrence relation results in , a significant improvement! But why?
Consider the tree formed by the recursion. At each successive level, the number of subproblems triple ( multiplications), but the size of each subproblem is halved ( bit length). That is,
- The tree's height is
- The branching factor is
At depth in the tree, there are subproblems of size . For each subproblem, a linear amount of work is necessary to identify the next subproblems and combine the answers. In other words, the time spent at depth (and only depth ) is
In other words, the overall time complexity can be represented by a finite geometric series.
Since the common factor of the geometric series is greater than , the runtime is dominated by the last term of the series, or the last level of subproblems. This is because this series increases extremely quickly from term to term. Thus,
This can actually be rewritten as by applying chain rule (for logarithms, not derivatives) in reverse:
*Note that, without Gauss's trick, the derivation comes out to , i.e. no improvement
2.2 Recurrence Relations
Divide and conquer algorithms all follow the same pattern. They split a problem of size into subproblems of size , and then combine these answers in time. This allows us to write their runtimes recursively with the equation
We can summarize this in a general "Master Theorem" that explicitly describes the time complexity of a divide and conquer algorithm parameterized by .
Master Theorem
If for constants , then
Proof. We follow the previous derivation for expression to find the finite geometric series
*Ensure this makes sense before proceeding. The finer details of derivation are purposely left out to force readers to think here :)
Case 1:
The series is decreasing. Since it is geometric, the first term dominates the sum, i.e. the time complexity is .
Case 2:
The terms of the series are all just . There are terms in the series, so the time complexity is .
Case 3:
The series is increasing. This is the same as the multiplication algorithm case. Thus, the last term dominates the sum, i.e. the time complexity is , as derived previously.
2.3 Mergesort
Mergesort is one of the most widely used sorting algorithms. The algorithm is a simple application of divide-and-conquer. It starts by splitting the array into halves, and recursing mergesort on each half. This propagates all the way down to singletons, i.e. arrays of size one. Then, we traverse back up the recursion step, merging the two arrays returned from our recursive calls into one sorted array. A diagram is displayed below.
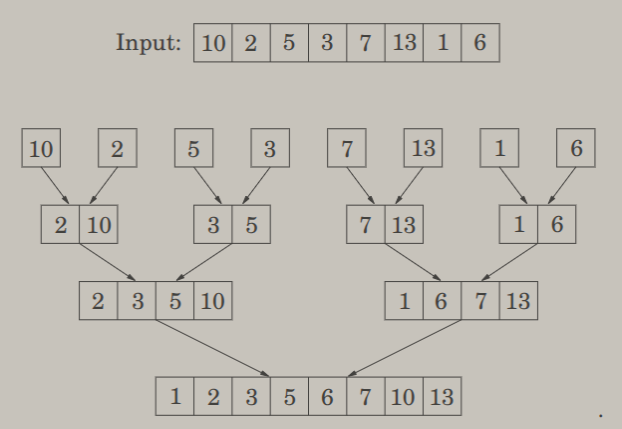
Merging can be done in , the subtree splits in at every level, and the subproblem size halves between levels. Thus, the recurrence relation is
Which comes out to be .
Mergesort can actually be made iterative by queuing all singleton arrays at the beginning, and at each step removing popping two arrays, merging them, and pushing them into the queue.
Once can actually note that the time complexity of general sorting (not including specialized sorting algorithms like radix sort) is , i.e. lower bound. This is derived by considering the number of comparisons required for sorting an array by creating a binary tree with all possible permutations as the leaves and comparisons as the intermediary (non-root and non-leaf) nodes. Thus, the depth of the tree (number of comparisons required) is at least . By Stirling's Formula,
Thus, , and sorting's time complexity is at least . Thus, mergesort is optimal!
2.4 Medians
The naive solution to find a median is sorting. However, this has time complexity. We can do better!
Randomized
Description
We can use a randomized divide-and-conquer algorithm. It is known as quickselect, and can actually be used for finding the th smallest number, not just the median. It is very similar to quicksort.
- Randomly pick a pivot point from the array
- Split into three arrays, defined as follows:
- Return one of the following, which may require recursion:
The three arrays can be computed from in time complexity. And, at each step, the subproblem shrinks to a size of .
Asymptotic Analysis
Since this is a randomized algorithm, its time complexity is dependent on the choice of pivot.
Worst Case
The worst case scenario occurs when our chosen pivot is always the largest or smallest element of the array. This will cause the subproblem to shrink by only one element each time, which results in a time complexity of
However, this is probabilistically impossible.
Best Case
The best case scenario occurs when our chosen pivot is always the median. This results in the recurrence relation
By the Master Theorem, this is just . Again, though, this is extremely unlikely to occur.
Average
Let be the chosen pivot. Let be good if it is within the interquartile range (25th to 75th) percentile of the array. Good choices of guarantee that . And we expect to pick, on average, choices of before getting a good .
Proof
Let be the expected number of choices before a good . If the current choice is good, we're done. If the current choice is bad, we need to repeat. Thus, . That is, .
Thus, on average, after two split operations, the subproblem will be at most of the original problem size. Therefore, we can write the average recurrence relation
Note that it would be since its two split operations, but we ignore constant factors as usual.
Using the Master Theorem, we can conclude that . In other words, the algorithm should return the correct answer in linear time complexity, on average.
Deterministic
Description
There also exists a deterministic divide-and-conquer version of that uses as pivot algorithm known as median of medians. It is parameterized by , the size of each subarray constructed. must be at least .
- Split the array into contiguous subarrays of size .
- Find the median of each array by calling the algorithm on each array. (Or, alternatively, using a naive subroutine since is generally small).
- Find the median of the medians by recursively calling the algorithm on the array of medians.
- The median of medians is used to choose to recurse on at most 70% of the array, with the exact proportion dependent on the value of in (assuming ). See [[#Deterministic#Asymptotic Analysis|below]] for an explanation of how the split works.
Asymptotic Analysis
We will choose for convenience of analysis, and analyze the time complexity of when using as a pivot selection algorithm.
 First, we will consider how we are able to eliminate 30% of the array. Consider the image above. Here, an array of 100 elements has been divided into 20 subarrays of size 5. The medians are all in row 3, and the median of medians is the element highlighted in red. Everything grayed out is less than the median of medians.
First, we will consider how we are able to eliminate 30% of the array. Consider the image above. Here, an array of 100 elements has been divided into 20 subarrays of size 5. The medians are all in row 3, and the median of medians is the element highlighted in red. Everything grayed out is less than the median of medians.
The properties of the median of medians guarantees that everything in the top left corner bounded by the row and column of the median of medians (row 1 to 3, columns 1 to 10). This makes sense because the median of medians is greater than all the median of all subarrays of size 5 before it, and the median of each subarray is greater than the elements above it in the table.
In other words, finding the median of medians allows us to identify with certainty the lower 30% of array elements. A similar thought process follows to identify the upper 30% of array elements.
Therefore, instead of fully partitioning the array based on a pivot, we can use the median of medians as a pivot and subsequently recurse on either the lower or upper of 70% of the array based on . We cannot recurse on the lower/upper 30% of the array because there exist some values not within those regions that are less/greater than the median of medians, respectively.
Thus, the recurrence relation is
The is for finding the median of the medians, the is for the next subproblem, and the is for the partitioning.
To derive the explicit time complexity it helps to draw out the tree for a recurrence relation of the form . I'm not dedicated enough to draw a tree, but you'll notice that the total sum of the subproblem sizes at the th level is . Since the combination step (partitioning) is complexity, the time complexity of the th level is . Note that this means the time complexity is simply a geometric series.
Where here represents the last level. Recall that, in previous proofs, either the first or last term dominates in a finite geometric series. Here, the common ratio depends on . For our recurrence relation, . Therefore, the first term dominates. That is,
2.5 Matrix Multiplication
We will assume we are multiplying 2 matrices. The naive algorithm for matrix multiplication is , as there are entries to be computed, and each requires time.
We can form a naive divide-and-conquer algorithm too, by splitting each matrix into blocks, and computing their products before combining. Unfortunately, the recurrence relation is
Which comes out to . However, Volker Strassen came up with a very clever improvement on this divide-and-conquer algorithm. In particular, he figured out how to compute the product of two matrices and from just seven subproblems.
Where
The new recurrence relation is
Applying the Master Theorem gives us .
Aside: Binary Exponentiation
Naive
The naive exponentiation algorithm to calculate is to just multiply with itself times. This has a time complexity of , if you consider multiplication as a constant time operation. However, multiplication is not constant time for binary exponentiation! Consider that the time complexity of multiplication grows with respect to the number of digits of the number (the maximum between the two being multiplied). Let have digits. Then has about digits, has about digits, ..., and has about digits. Thus, the number of digits grows with respect to . Therefore, this has time complexity .
Binary
Instead of doing that, we can use the following algorithm.
def exp(a, n):
if n % 2 == 1: return a * exp(a*a, n>>2)
else: return exp(a*a, n>>2)
This has time complexity without considering the time complexity of multiplication. Considering the complexity of multiplication, it has time complexity .
Aside: Fibonacci Sequence
Naive
The naive algorithm for the Fibonacci sequence is simply to do a simple recursion.
def fib(n):
if n == 0: return n
if n == 1: return n
return fib(n - 1) + fib(n - 2)
However, this has exponential time complexity. We proceed via induction.
The recurrence relation is . We seek to prove that the time complexity is .
Base Case:
Trivial.
Inductive Hypothesis:
Assume the time complexity is for .
Inductive Step:
Thus, the time complexity is . In fact, we can product an even tighter bound of , where is the golden ratio. This can be intuitively explained as follows.
Assume , where . Then,
Dynamic Programming
We can definitely compute it faster though! Notice how we are recomputing values we already computed? (In other words, calling Fib with the same argument multiple times). We can instead memoize this, remembering what the output of Fib was for that input.
def fib(n):
dp = [0 for _ in range(n + 1)]
dp[1] = 1
for i in range(2, n + 1):
dp[i] = dp[i - 1] + dp[i - 2]
return dp[n]
This allows for linear time complexity... right?
Sorta. If you consider addition to be an operation, then, yes, this is . Technically, addition is an operation for the Fibonacci sequence! Let's set some bounds for the Fibonacci sequence.
But also, since ,
Therefore, . With this, is a good approximation of the number of digits of . (Technically, , but constant factors don't matter). Therefore, the addition operation actually takes time complexity for calculating .
We thus must consider the number of steps for the addition operation at every step of the for loop. The total sum is
Thus, the dynamic programming method actually has a time complexity of .
Binary Matrix Exponentiation
We can note the following formula for calculating the Fibonacci sequence:
Extrapolating, we get
Through matrix diagonalization, we can make the time complexity of binary matrix exponentiation essentially equivalent in time complexity to [[#Binary|binary integer exponentiation]]. Thus, the fastest algorithm is actually .
*Note that taking the limit of this matrix exponentiation produces the golden ratio , as confirmed in the previous algebraic derivation of .
Aside: Closest Pair
Given a set of points in a plane, calculate the Euclidean distance between the closest pair of points.
Naive
There is clearly an algorithm that checks the distance between every pair of points, and finds the minimum.
Divide and Conquer
Algorithm
Choose a pivot point in the middle of the points in terms of -coordinate. Divide the graph into two sets and , corresponding to points left and right of the pivot, respectively. Then, calculate the closest pair distance in and the closest pair distance in by recursing the algorithm on these subproblems. Let denote these distances. Let . We can prove some properties for this problem.
Property 1: If , , and (distance between and ) is less than , then and .
Proof: We proceed via proof by contraposition. Let lie outside the region of the plane where . Since , Then, it is guaranteed that .
Property 2: Any tile that is in size that is entirely contained in or can have at most one point.
Proof: We proceed via contradiction. Assume and are contained in . Then, . That is, this pair of points would have formed the closest pair in or , which is a contradiction.
Property 3: Let lie inside the region of the plane where . Then, there are at most points in within the same region such that and could be less than .
Proof: Consider the region within the aforementioned region where lies in the vertical bottom of the region. Subdivide the region into squares, and arbitrarily assign to one of the squares it borders. Consider that any point above this region certainly has . Therefore, must exist within one of the other squares there are at most points in within the same region such that the statement is true.
We can now describe the algorithm.
- First, we preprocess the set of points , producing a list , the set of points sorted by , and , the analogue for .
- We define a function
- Let . If , just brute force.
- Choose the middle pivot point, "middle" in terms of . Partition into and in time. Partition into and in time. These lists should remain sorted according to their subscript.
- Recurse on the subproblems. That is, and . Then, ,
- Define the middle region (strip) and conquer. We write the pseudocode here:
# construct strip, sorted by y strip = [] for p in Py: if abs(p.x - pivot.x) < d: strip.append(p) # process closest pair candidates k = len(strip) for i in range(k): for j in range(i + 1, k): # this will run at most 7 times if strip[j][1] - strip[i][1] >= d: break d = min(d, distance(strip[i], strip[j]))
Time Complexity Analysis
Preprocessing takes time. Partitioning takes time. Recursing on the subproblems takes time. Processing the strip takes time, with a small constant factor. The recurrence relation is thus
By the Master Theorem, . Since preprocessing also has time complexity, the overall algorithm has time complexity!