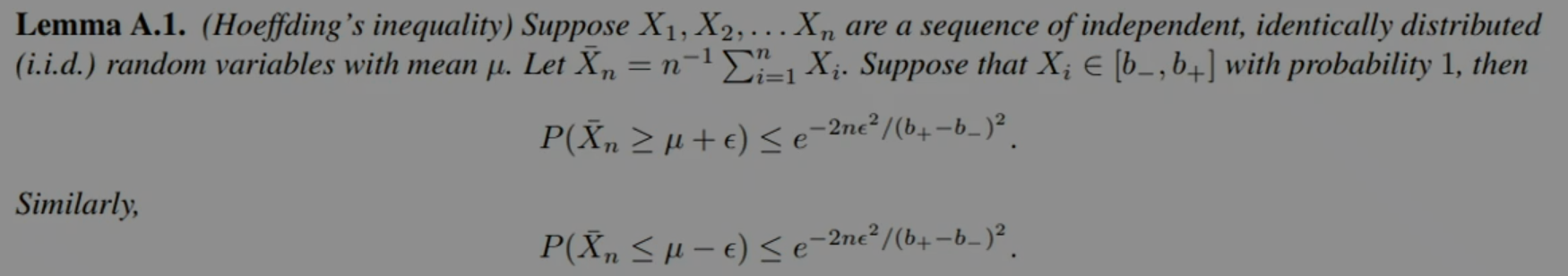First, there are some interesting questions asked in RL theory.
If I use algorithm A with N samples for k iterations, what is the worst case performance (under some set of assumptions)?
For instance, determining the number of iterations k of Q-learning to produce ∥Q^k−Q∗∥≤ϵ with probability ≥1−δ if N≥f(ϵ,δ).
Or, determining the number of iterations k of Q-learning such that ∥Qπk−Q∗∥≤ϵ.
For some exploration algorithm A, how high, in the worst-case, is the regret?
And many others!
In analyzing RL theory, it's also necessary to make some strong assumptions to achieve any interesting results, while not deviating too far from reality. For...
...exploration: how likely are we to find (potentially sparse) rewards? In the worst case, it's extremely hard; thus, there are typically some assumptions made to produce interesting bounds.
...learning: how many samples do we need to effectively learn a model/value function? Often, a "generative model" assumption is made that assumes we can sample from p(s′∣s,a) for any (s,a) (assumes exploration is not too hard). Alternatively, an "oracle exploration" assumption assumes sampling from p(s′∣s,a) for each (s,a) up to N times.
The point of this is not to prove that an algorithm works perfectly every time (in fact, in deep RL, typically not even convergence is guaranteed). However, it does yield interesting conclusions on the effect of problem parameters/hyperparameters on error—RL theory produces qualitative conclusions about various factors under strong assumptions that are reasonable enough such that they may guide decisions in real RL problems..
Note that r is a vector, and Qπ,P,Pπ,Vπ are all matrices.
That final equation actually gives us a method of recovering the Q-function, but is impractical not just for the typically high dimensionality of the state and action spaces but because we typically do not assume knowledge of Pπ (involves state transition probabilities). Notably, though, that last equation tells us that policy evaluation is essentially just a linear operation.
Now, say r≈1. From this, we can note that ∑t=0∞γtr≈∑t=0∞γt=1−γ1. Thus, the total reward of a trajectory is approximately 1−γ1, and thus our Q-function matrix Qπ has elements that are roughly 1−γ1 in magnitude. Alternatively, for a finite horizon problem (and no discounting), we have that the total reward of a trajectory is approximately ∑t=1Hr≈H, and our Q-function matrix Qπ would have elements that are roughly H in magnitude. Therefore, for infinite horizon tasks with discounting, we can roughly term 1−γ1 as a "finite horizon" for the problem.
Convergence of Value Iteration
In linear algebra notation, value iteration is V←maxa[r+γPV]. Let's define an operator T such that
TV=amax[r+γPV]
this is known as the Bellman optimality operator. Also, let us note the following useful inequality
∣xmaxf(x)−xmaxg(x)∣≤xmax∣f(x)−g(x)∣
Consider, now, two value functions V(s) and U(s). We'll apply the Bellman optimality operator to both, and consider the difference.
Thus, applying T to any two value functions V and U will "bring them closer" w.r.t. to the infinity norm.
Also, we will note that TV∗=V∗, or that the optimal value function does not change by application of the Bellman optimality operator. We will not prove this fact for brevity.
First, let's define our algorithm and assumptions. We will assume "oracle exploration," i.e. we can sample s′∼p(s′∣s,a) for each (s,a) up to N times. Our algorithm is a simple "model based" algorithm.
p^(s′∣s,a)=N#(s,a,s′).
Given π, use p^ to estimate Q^π.
Then, we'd like to answer the following questions.
How close is Q^π to Qπ?
How close is Q^∗ to Q∗ if we learn it using p^?
How close is the final policy Qπ^∗ to Q∗?
We'll first address question 1, where we define (ϵ,δ)-closeness as ∥Qπ(s,a)−Q^π(s,a)∥∞≤ϵ with probability at least 1−δ if N≥f(ϵ,δ). Note that we use ∥⋅∥∞ because it provides worst-case performance bounds.
Concentration Inequalities
Now, relating samples to errors is highly nontrivial. We will need a concentration inequality; Perhaps the simplest such inequality is Hoeffding's inequality.
Intuitively, the interpretation is that if we estimate μ with n samples the probability we're off by more than ϵ is at most 2e−2nϵ2/(b+−b−)2.
Equivalently, if we want this probability bound to be δ, we can show that we require
2nb+−b−logδ2≥ϵ
Importantly, ϵ∝n1.
However, we are estimating sample probabilities, not sample averages. For that, we need a different concentration inequality.
From this, we derive
δ≤N1logδ1
and we may apply this to our problem and write
∥p^(s′∣s,a)−p(s′∣s,a)∥1≤∣S∣(N1+ϵ), with probability 1−δ=N∣S∣+N∣S∣logδ1≤cN∣S∣logδ1
for some constant c.
Useful Lemmas
We'd like to now relate the error of p^ to the error of Q^π. We can note that
QπVπPπ=r+γPVπ=ΠQπ=PΠ
Note that Π represents the matrix of π(a∣s) for all (s,a), and P represents the matrix of p(s′∣s,a) for all (s,a,s′). These directly imply that
QπQπ=r+γPπQπ=(I−γPπ)−1r
Comparing this with the previous equation derived for Q^π, we note the similarity
QπQ^π=(I−γPπ)−1r=(I−γP^π)−1r
Then, we claim the following simulation lemma is true.
Another useful lemma is that, for some Pπ and any vector v∈R∣S∣∣A∣, we have that
∥(I−γPπ)−1v∥∞≤∥v∥∞/(1−γ)
this is basically just a formalization of an obvious fact using the geometric series application with γ previously. It's really just stating that, in policy evaluation, the maximum Q-function value is bounded by the maximum reward seen across all time steps multiplied by the effective horizon 1−γ1.
Note that ∥Vπ∥∞≤1−γ1Rmax because of the same geometric series trick, and we can actually assume WLOG Rmax=1 because, if they aren't, we can simply rescale the rewards appropriately (if we multiply the rewards by any constant, the optimal policy doesn't change). Thus, ∥Vπ∥∞≤1−γ1. Thus,
We note that Q^π^∗ is essentially just Q^∗, and so the first term is bounded by ϵ according to our second derived bound, ∥Q∗−Q^∗∥∞≤ϵ. Meanwhile, the second infinity norm is bounded by ϵ according to our first derived bound, ∥Qπ−Q^π∥≤ϵ, where π=π^∗ here. Thus,
∥Q∗−Qπ^∗∥∞≤2ϵ
Analysis of Model-Free RL
We'll now analyze fitted Q-iteration.
First, let T be the Bellman operator such that
TQ=r+γPamaxQ
Then, exact fitted Q-iteration may be defined as Qk+1←TQk. For approximate fitted Q-iteration that uses samples, it changes slightly to be Q^k+1←argminQ∥Q^−T^Q^k∥. T^ is the Bellman operator, except it accounts for sampling by considering the effective frequency of observations of each s′. In particular, we define T^ as
However, our update rule now involves a norm—what norm should we use? Unfortunately, the algorithm won't actually converge if ∥⋅∥2 is used; therefore, we will assume ∥⋅∥∞. Notably, no such learning algorithm exists that may train with the infinity norm, and mean squared error is of course used in practice. Some interesting properties of the MSE-based learning algorithm are provable; however, they are much more difficult. Thus, we proceed with a theoretical learning algorithm that works with the infinity norm.
Now, we'd like to answer the following question: as k→∞, Q^k→? or limk→∞∥Q^k−Q∗∥∞≤?. Where does our error come from though? For approximate fitted Q-iteration, from sampling error, T=T^, and approximation error, Q^k+1=T^Q^k.
Sampling Error
Let's first understand the effect of sampling error.
Where the inequality applied is triangle inequality. For the first term, the estimation of a continuous random variable, we can use Hoeffding's inequality.
∣r^(s,a)−r(s,a)∣≤2Rmax2Nlogδ1
Meanwhile, for the second term, we can use the other concentration inequality
Recall the substitution of Q∗ with TQ∗ in step 2 is possible because Q∗ is a fixed point of the operator T. The last step leverages the fact that T is a γ-contraction. We can recurse through this last inequality to produce
Notably, the ∥Q∥∞ in the sampling error bound is in O(Rmax1−γ1). (Recall from previously that the entries of the Q-function matrix are approximately the size of the horizon, assuming r≈1). Meanwhile, there exists a 1−γ1 scalar for the approximation error bound. Thus, error compounds with quadratically with the horizon, since the error for each step ∥Q^k−TQ^k−1∥ scales with the horizon and there are H steps for a horizon H.