Lecture 3
Solution 2: Better Models, Less Mistakes
Why might a model fail to fit to the expert (training data)? The human expert may exhibit...
- Non-Markovian behavior
- Multimodal behavior
Non-Markovian Behavior
Instead of , a human's policy resembles something more like , in which the current behavior depends on all past observations, not just the current observation. This sort of knowledge can be encoded by using some sort of sequence model, e.g. transformer, to process each observation "frame" in history.
If there is a bijection between observations and states (i.e. ), then there exists a Markovian policy (i.e. doesn't use history) that is optimal. If the observations are not sufficient to infer the full state, then the optimal policy may require knowledge of history.
However, including history can degrade model performance. Why?
- Access to more (unnecessary) information can cause mistakes.
- It may induce overfitting as the model must naturally be larger and have more capacity.
- It can increase the chance of distributional shift, as even one small deviation remains in the history forever, and therefore contributes to the shift from then on.
Causal confusion is a particularly notable consequence of an excess of information. In essence, a model's action causes an event , which results in and showing up together very frequently. As the model makes associations, not causal relationships, the occurrence of can actually influence the model into doing . This phenomenon is known as spurious correlation.
When the car brake is depressed (), the brake indicator lights up (). As the brake remains depressed over the next several time steps, so too will the brake indicator remain lit up. Then, during inference, if the model sees the brake indicator light up, it may likely choose to depress the brake because it has associated action with event .
DAgger, surprisingly, is effective for fixing causal confusion for the simple reason that DAgger addresses distributional shift.
Multimodal Behavior
Multimodal behavior describes environments where there exist states for which there are multiple reasonable actions. This becomes an issue with continuous actions, in which a unimodal distribution (e.g. Gaussian) would essentially average the reasonable actions together to produce an action that may not be reasonable at all! There are a couple solutions to this.
- Discretize the continuous action space softmax correctly identifies all reasonable actions
- Use more expressive continuous distributions multimodal distributions that capture all reasonable actions
Discretization
Can we always just naively discretize continuous action spaces? No, because the number of discrete "bins" is exponential in the dimensionality of the action space. For low-dimensional action spaces, however, this is a great solution.
One may suggest discretizing one dimension at a time to avoid the exponential explosion; however, this is not necessarily effective because it suggests choosing along each dimensions independently when, in fact, the dimensions may covary with each other.
For instance, consider a highway with a fast lane on the right and a slow lane on the left. One dimension of the action space is , and another dimensions of the action space is . However, the two dimensions are not independent—the only good actions here are and .
Autoregressive discretization provides a computationally efficient (linear, not exponential) solution for high-dimensional action spaces. In essence, this discretizes one dimension at a time, but in sequence, rather than independently. In essence, the sequence model (e.g. transformer), when predicting dimension of the action space, is fed the original input (state/observations) and the previously predicted dimensions, i.e. dimensions . In short, the dimensions are discretized one a time and then decoded autoregressively (hence the nomenclature).
This is valid by the Chain Rule of Probability. If we denote dimension of action as , then
In other words, this is equivalent to predicting all dimensions of the action at once based on the state while still providing an efficient method of discretization.
Expressive Continuous Distributions
Generally speaking, it's hard to model multimodal distributions. Instead, we can include an additional input that "decides" the mode that the model chooses; this additional input can simply be some random noise.
The main challenge with this method, however, is that we must train the model to actually use the random noise to decide the mode—otherwise, of course, the noise is useless. There are several different solutions for this.
- Variational autoencoders
- Normalizing flows
- Diffusion/flow matching
Diffusion/Flow Matching
Diffusion is the most popular approach for generating high dimensional, continuous data. The key principle underlying diffusion is that turning random noise into a specific image (e.g. image of a dog) is hard, but turning an image of a dog into random noise is easy (just add more noise). So, to train a model to generate images of dogs, we take real images of dogs, iteratively add noise, and then train the model to simply go the other way!
 Source: GeeksforGeeks
Source: GeeksforGeeks
Flow matching is the modern version of diffusion, with essentially the same intuition, except it's easier to implement. In essence, we want to train a model to start with a noise distribution, e.g. Gaussian, and transform samples from it into a desired data distribution. It relies on the same idea of starting with real data samples and adding noise, and simply training the model to reverse this process. Formally, flow matching learns a vector field that allows "sampling from" (modeling) by sampling (noise distribution) and integrating the vector field to produce . In practice, this integration is discretized as Euler integration. Below is a demonstration of flow matching in action.
But how do we train flow matching?
- Sample (i.e. Gaussian noise distribution)
- Sample where (data distribution)
- Sample where is defined only over (e.g. ), as this is the selection of the "time step" of the vector field in-between , the noise distribution, and , the data distribution. See the below diagram for clarification.
- Compute (i.e. just draw a line)
- Update with , or update the velocity (that point in the vector field) to point more towards (i.e. intended velocity is the slope of the line )
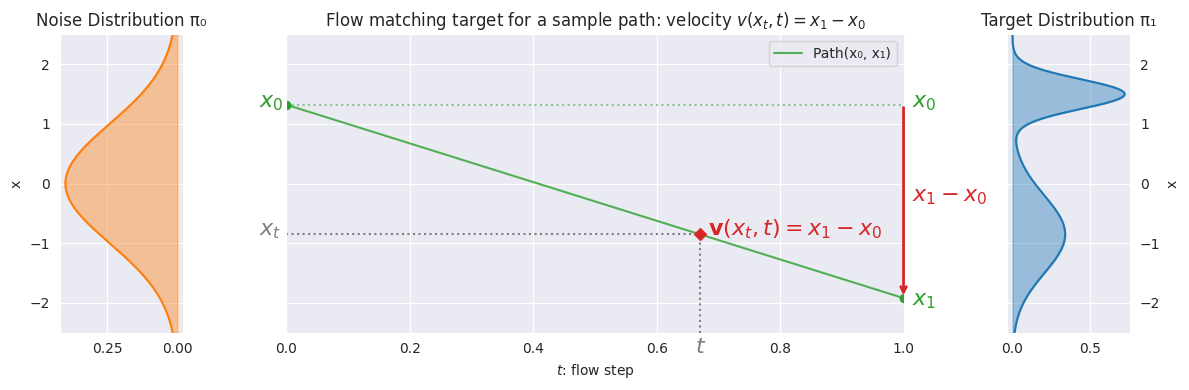
The point of this with regards to fixing the averaging problem is that the vector field produced by flow matching will eventually diverge to produce one of the reasonable actions. In earlier "time" steps ( closer to ), the vector field appears more averaged across reasonable actions. When is closer to , the vector field starts to diverge. In essence, the supervision of many linear vector fields produces an overall vector field that effectively maps the noise distribution to the target distribution, effectively representing multimodality.
In RL, flow matching is applied as follows.
- Construct minibatch. For each element in batch ,
- Sample from dataset (data distribution)
- Sample (noise distribution)
- Sample (time step)
- Compute .
- Update , where .
That is, when applying flow matching to RL, the model is predicting the vector field/velocity itself. In particular, the model is represented by .
Action Chunking
Action chunking asks a model to predict a chunk or sequence of the next actions, after which the actor will execute the first actions, where . It's unknown exactly why or when this improves performance for imitation learning, but it frequently does!
There is no definitive reason, but it seems that it provides additional training signal for the model.
Solution 3: Narrow vs Broad Data
In practice, how you collect/augment your datasets has a substantial impact on model performance.
Mistakes and Corrections
One common method is to intentionally add mistakes (and their corresponding corrections) to the dataset. This ensures the dataset isn't "too good," and that the model can learn to recover from the mistakes, and the idea is that the inclusion of corrections helps more than the mistakes hurt the model. This addition of data may even be synthetic.
Pre-Training
Essentially, the motivation is the same as the mistake-augmentation; we want to show the model bad situations and how to recover from them, but not to enter those situations. So, we run two steps of training.
- Pre-training phase: train the model on a very large, but low quality dataset that may include many mistakes.
- Post-training phase: train the model on a smaller, but curated/high quality dataset that only includes good examples. (This is known as fine-tuning).
Solution 4: Multi-task Learning
Consider training a car to drive to a single point , with policy . An example of a multi-task version of this problem would be training a car to drive to any of a set of points , with policy , i.e. conditioned on some choice of .
The most obvious benefit of this is that this allows a much larger and varied corpus of training data, and this is more formally known as goal-conditioned behavioral cloning, in which the model is trained on a dataset of several tasks, but it takes in, as input, the desired goal—in this case, which point the car should drive to.