Chapter 3: Finite Markov Decision Processes
Markov decision processes (MDP) are the classical formalization of sequential decision making, where actions influence beyond just immediate state and reward.
3.1 The Agent-Environment Interface
In an MDP, the learner/decision-maker is called the agent, while what it interacts with is called the environment.
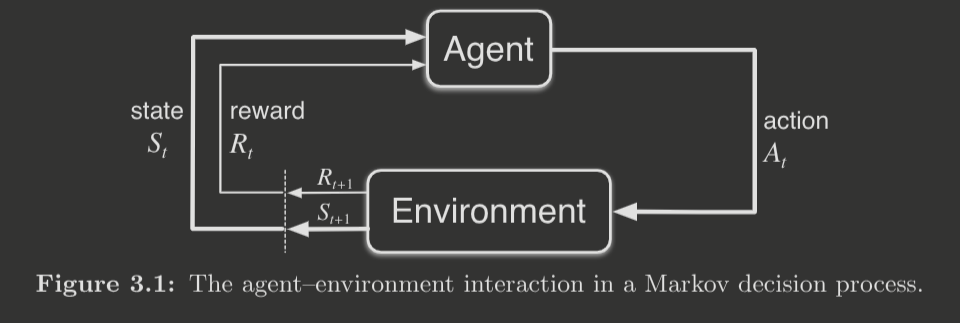
The iterative interactions between the agent and environment produce a trajectory
where the reward resulting from taking the action in state is , which is denoted as such because is really received at time step .
In a finite MDP, the number of possible states, actions, and rewards is finite, and all associated probability distributions are thus discrete. In particular, are all random variables described by discrete distributions.
The function
fully describes the dynamics of the MDP. In other words, the probability of depend solely on the preceding state and action, and . Critically, they do not depend on earlier states and actions. This quality of the MDP is known as the Markov property.
Using the four-argument dynamics function, one may calculate several other important expressions. For instance, the state transition probability function,
the expected reward function,
and the expected reward function for tuples,
As it turns out, this MDP framework is very flexible, and may be applied to many goal-directed learning problems!
3.2 Goals and Rewards
In RL, the goal of the agent is formalized/represented by a reward, a numerical signal that the agent will aim to maximize. This is known as the reward hypothesis: the goals are represented by the maximization of the expected value of the cumulative sum of a scalar signal (reward).
The reward signal should not be used to express a prior describing how we think the agent should behave. It should only embody the problem goals.
3.3 Returns and Episodes
As aforementioned, the agent's goal is to maximize the cumulative sum of rewards. This is known as the return , defined as
where is the final time step. Notably, is only finite when there is a sensible choice of a final time step, i.e. in which the agent-environment interaction process can naturally be broken into subsequences, or episodes. Typically, each episode will end when the agent reaches a terminal state. Note that the set of nonterminal states is denoted and the set of all states (including terminal states) is denoted . Moreover, is a random variable that varies between episodes. This problem setting is known as an episodic task.
Otherwise, when , i.e. there is no natural separation of the interaction process into episodes, this is known as a continuing task.
For continuing tasks, the above expression for the return is actually problematic! This is because the return can become infinite. Thus, a technique known as discounting is typically applied, with a discount rate being included in the formula
where . If , will be finite, provided the reward sequence is bounded. If , the agent is myopic in that it prioritizes only immediate rewards. Notably, with discounting, we may write a recursive formulation of the return.
3.4 Unified Notation for Episodic and Continuing Tasks
We note that the episodes in an episodic task are almost always identical, since they begin from the same starting state and the state transition probabilities are the same. Thus, rather than denoting the state at time for episode as , we assume henceforth we are just analyzing a single episode in isolation for an episodic task, and denote the state at time as just .
Additionally, we may frame an episodic task as a continuing task by creating an absorbing state that follows directly from a terminal state, and simply loops infinitely on itself with a reward of .
Thus, the combination of these two things allows the same exact notation for episodic and continuing tasks, and we may write
for both types of tasks.
3.5 Policies and Value Functions
Practically all RL algorithms estimate value functions, functions that map a state or state-action pair to some estimate of its "value" (return). Value functions are defined with respect to a policy , which maps a state to a probability distribution over the action space, i.e. .
Formally, the value function of a state under a policy , , is the expected return of starting in and following thereafter.
This is known as the state-value function for policy .
We may similarly define an action-value function for policy , , which returns the expected return of starting in , taking action , and following thereafter.
It's not possible to know the true value functions (at least, in most practical use cases), but they may be estimated based on the agent's interactions, by averaging the measured returns for each state/state-action pair. Such estimation methods are known as Monte Carlo methods because they average over many random data samples. We discuss such methods further in Chapter 5.
It's usually not possible to keep averages for every single state when faced with extremely large state spaces. Instead, these functions are modeled using only much fewer parameters. (e.g. neural networks!)
Notably, these value functions also satisfy recursive relationships.
this is known as the Bellman equation for the value function , and expresses the recursive relationship between the value of a state and the value of successive states. It may be visually displayed via a backup diagram, which diagrams the update or backup relationships for the value function.
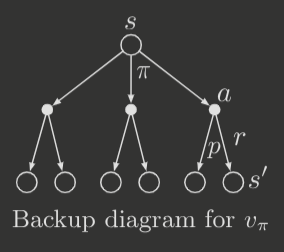
Also, note the following relationship,
which should hopefully be intuitive.
3.6 Optimal Policies and Optimal Value Functions
Solving an RL task, at its core, means finding an optimal policy. Notably, value functions define a partial ordering over policies, where a policy if . Consequently, there is always an optimal policy that is all other policies. We denote such a policy (though there may be multiple) as . Note that all optimal policies share the optimal state-value function, defined
Similarly, they share the optimal action-value function, defined
Note that we may relate the two, i.e.
We may also substitute the Bellman equation to derive the Bellman optimality equations, which is really just a mathematical formulation of the idea that "the value of a state under an optimal policy is equivalent to the expected return for the best action from that state."
and
For finite MDPs, the Bellman optimality equations actually have unique solutions, and may be obtained by solving a system of nonlinear equations.
3.7 Optimality and Approximation
In practice, optimality is an ideal that agents can only approximate, not only because we usually have an imperfect model of the environment but also because the Bellman optimality equation is not easily solvable due to the massive state and action spaces.