Chapter 14: Reliable Storage
"The central question of this chapter is: How can we make a storage system more reliable than the physical device out of which it is built?"
The question of reliability actually revolves around 3 principles.
- Reliability - the ability of a system or component to perform its required functions under stated conditions for a specified period of time (IEEE definition)
- Availability - the probability that the system can accept and process requests (the proportion of time for which a system works as intended, with regards to access)
- Durability - the ability of a system to recover data despite faults
Persistent storage systems, in particular, must deal with two threats to reliability.
- Operation Interruption - some sort of failure or crash midway through an operation can leave data in an inconsistent state, which the system cannot make sense of.
- Loss of Stored Data - non-volatile storage media can fail, causing data to be lost.
To address this, there are two mainstream solutions, one for each issue.
- Transactions - essentially, a way to make a sequence of non-atomic operations function as an atomic unit. The system's state either reflects the entire sequence's changes, or none.
- Redundancy - checksums, error correcting codes, or any other way of cleverly "duplicating" data to detect or recover from lost or corrupted storage devices.
14.1 Transactions
Pre-Transactional Approaches
Many older file systems used ad-hoc approaches to solve the problem of interrupted operations.
FFS, for instance, would simply ensure that any changes to the disk were always completed in a specific order. Then, if a crash occurred during a group of updates, a disk scan could identify the inconsistency and repair the data structures. This disk scan, for FFS, was the fsck utility.
However, this approach has largely been abandoned during modern times for a few reasons.
- Complex Reasoning. Like multi-threaded concurrency, this approach quickly becomes complicated to reason about as systems grow more complex.
- Slow Updates. File systems are forced to insert barriers between dependent operations, reducing pipelining and parallelism.
- Slow Recovery. After a crash, a machine must scan all of its disks for inconsistencies. As persistent storage rapidly grew, the resulting overhead grew larger and larger.
Transaction Abstraction
As aforementioned, a transaction abstracts a sequence of several operations as a single, atomic unit. A transaction finishes in one of two ways, it...
- commits, meaning the effects of its underlying operations are visible in the system.
- rolls back, meaning the effects are not reflected by the system.
A transaction, at its core, aims to fulfill the four ACID properties. (These are most commonly referenced in database system design, but really apply to any system desiring reliability).
- Atomicity - updates are "all or nothing." Transactions that commit see all updates take effect, while those that roll back see zero updates take effect.
- Consistency - the system is always in a legal state, i.e. a transaction brings the system from one legal state to another. More formally, a transaction guarantees that the system's invariants that hold at the start of the transaction also hold at the end of the transaction.
- Isolation - transactions appear to execute on their own. In other words, concurrently executing transactions do not affect each other.
- Durability - once a transaction is successfully committed, its changes are permanent and will not be lost, even after system failures.
Transaction Implementation
A transactional file system must deal, of course, with the inherent fact of persistent storage devices—their only atomic operation is writing a single sector or page. Typically, they do this by, before executing a transaction itself, recording a transaction's intentions in persistent storage, i.e. the operations it intends to perform. Only once these are all safely stored, the transaction should begin to perform its operations; any interruption can be recovered by the system re-executing the stored intentions.
Redo Logging is one way of doing exactly this. It consists of four stages.
- Prepare. Append all planned updates to the log.
- Commit. Append a commit record to the log, indicating that the transaction has committed. (Or, it may be rolled back. In this case, simply not writing a commit record may suffice.)
- Write-back. The transaction's updates are actually carried out.
- Garbage collect. Finally, the transaction's updates in the log are removed.
Note that step 2 is known as the atomic commit. Before that moment, the transaction may safely be rolled back; after step 2 completes, the transaction must take effect. This becomes clear after understanding the recovery routine: for each record in the log (scanning sequentially), if it is...
- an update record for a transaction, then add this record to a sequence of planned updates for this transaction.
- a commit record for a transaction, then write-back this transaction's logged updates (i.e. the sequence of planned updates for this transaction)
- a rollback record (if rollback records are supported), then discard the sequence of planned updates.
When the end of the log is reached, any remaining sequences of planned updates are discarded, as these transactions did not have commit records in the log!
There are, however, a few key details that must be observed.
- Concurrent transactions - if multiple transactions are being executed at the same time, each record must identify the transaction it belongs to.
- Asynchronous write-back - write-back may be delayed as far back as desired; what matters is the commit record. This allows flexibility for minimizing latency between a commit and the function itself returning, as well as optimizing throughput by batching writes together.
- Repeated write-back - since an update record in a transaction may be repeated/written-back multiple times, each operation must be idempotent—that is, it should have the same exact effect regardless of how many times it is executed.
- Recovery crashes - the system must be able to recover from crashes during a recovery. This is largely guaranteed by the redo log structure and idempotence already.
- Garbage collection implementation - it's evidently necessary to reclaim space for transactions that have been fully written back. This is usually done by keeping several persistent pointers—one for the most recent record that has been garbage collected, one for the most recent record that can be garbage collected, and one for the most recently added record—and using a circular log.
- Ordering is important - reordering a transaction's steps (i.e. doing write-back before committing) can lose the guarantees of atomicity.
Undo Logging
Transactions can also be implemented via undo logging, which essentially just replaces logging the transaction's intentions with logging the old version of the object. In the event of a failure, the system simply writes the old version of the object back into place. However, undo logging frequently requires more random I/Os (and just more I/O in general, especially if objects are large) and gives up the flexibility (and performance) of asynchronous write-backs. Thus, redo logging is more commonly used.Undo/redo logging involves logging both the old and new versions of an object. This allows redoing the updates of committed transactions and undoing the updates of uncommitted transactions.
What happens if concurrently executing transactions operate on the same shared state? Then, these transactions may not actually appear atomic. To address this, one popular method is two-phase locking (2PL). This divides a transaction into two phases: during expanding (pre-commit), locks are only acquired; during contracting (post-commit), locks are only released. 2PL helps ensure a strong form of isolation known as serializability, i.e. the results appear as if the transactions are processed sequentially, one at a time.
Notably, 2PL has the risk of introducing deadlock. Transactions, though, provide a simple solution themselves! If a set of transactions deadlocks, one or more transactions are rolled back, release their locks, and are queued for execution later.
MVCC is an alternative to locks for enforcing transaction isolation. It is, essentially, the concept of RCU Locks abstracted and applied to transactions.
The strict requirements of serializability inevitably impact performance, as it forces transactions to, at times, block or roll back. In some cases, it may be beneficial to relax isolation requirements to improve performance. For instance, snapshot isolation only requires that each transaction's reads appear to come from a "snapshot" of the system's committed data when the transaction starts. Transactions are buffered until they commit; then, the system checks for write-write conflict, essentially two transactions attempting to modify the same object with overlapping transaction times. If there exists a write-write conflict, the transaction being committed is rolled back. Note that snapshot isolation is weaker than serializability because a transaction's reads and writes happen at logically separate times (i.e., you can imagine that each transaction is split into one operation of reads and one operation of writes, and serializability is only guaranteed after this split). This allows write skew anomalies, where a transaction reads object and updates object , while a concurrent transaction reads object and updates object .
Finally, let's discuss the performance of redo logging. Surprisingly, it's not too bad, despite seemingly duplicating every single write (once to the log, once to the actual data). This is for several reasons.
- Sequential Log updates - this translates to a very fast log, as sequential writes are, as frequently discussed, much better than random writes.
- Asynchronous Write-Back - since write-back can be delayed until some time after the system "returns," the latency is largely masked and the updates may be batched, improving throughput.
- Fewer Barriers/Synchronous Writes - in the end, transactions serve as a replacement to the ad-hoc reliability solutions like FFS's careful ordering, which we know to require barriers and synchronous write operations, which ultimately reduce pipelining and parallelism. Transactions do need barriers too, but only a few per transaction.
- Group Commit - group commit is an optimization that combines a set of transaction commits into one log write to amortize the costs of writing commit records to disk, and effectively reduces some of the disk I/O overhead.
Transactional File Systems
Finally, we discuss the actual details of transactions in file systems. Traditional, update-in-place file systems were one of two types.
- Journaled - Only updates to a system's metadata are included in transactions, while updates to user's files are simply done in-place. This ensures consistency of the file system, but has fewer guarantees regarding the state of contents of regular (non-directory) files. However, it does have the benefit of better performance, as not logging the contents of regular files avoids the overhead of large writes.
- Log-Structured - All updates to disk (both metadata and data) are included in transactions. In other words, all updates are logged, and then at some point in the future the system performs all the updates at once, essentially batching all the requests.
Many modern file systems, though, are copy-on-write. They offer several performance optimizations over journaled and log-structured file systems.
- Batched Updates - this transforms small, random writes into a few large, sequential writes and actually reduces how many blocks must be written by coalescing multiple updates of the same indirect blocks and inodes.
- Intent Log - essentially, an optimized redo log to support the batched updates. By default, writes are only written to the intent log if they are forced to disk, and the intent log may also use a separate, dedicated logging device that is much faster than the main storage device.
14.2 Error Detection and Correction
Storage systems include multiple defenses against device failures.
- Storage devices themselves detect failures with checksums and correct small corruption with error correcting codes
- Storage systems include redundancy using RAID architectures to reconstruct corrupted data
- File systems/software include end-to-end correctness checks
We'll discuss each of these in turn, separately.
Storage Device Failures and Mitigations
Individual storage devices—whether magnetic disk or flash—can fail in two distinct ways.
- An isolated disk sector or flash page can lose existing data or degrade to the point where it cannot consistently store new data
- An entire device can fail
Sector/Page Failures
Storage devices use two mitigation techniques.
Error Correcting Codes
Error correcting codes are a clever way of encoding data such that an error in a small number of bits within a page can be fixed automatically by the device hardware.
Remapping
Disks and flash devices typically include some number of spare sectors/pages. When a sector or page permanently fails, the OS or device firmware can remap the failed sectors/pages to good, spare ones.
Device Failures
When a whole storage device fails, the host computer will detect this failure, and any reads/writes will return error codes. Failure rates are typically described by an annual failure rate or the mean time to failure (MTTF). In general, "the number of failure events in a fixed time period can be mathematically modeled as a Poisson process, as the interarrival time between failure events follows an exponential distribution."
RAID
RAID, or Redundant Array of Inexpensive Disks, is a system that cleverly distributes data redundantly across several disks for the purpose of recovering data in the event of an individual disk failure. The two most commonly discussed RAID architectures are
- RAID 1 (Mirroring) - quite simply, the data in one disk is always duplicated to another disk.
- RAID 5 (Rotating Parity) - essentially, given disks, data blocks are distributed across of the disks, and a parity (redundancy) block is written to the last disk. Typically, this parity block is simply the XOR of all the other blocks; thus, if any one disk fails, each block within it can be recovered using the other blocks and the parity block (from the remaining disks).
Notably, there are a couple performance considerations to be had with the organization of rotating parity redundancy.
- Rotating the parity block - the parity block must be written to every time a block within its set of blocks is updated. Therefore, to balance load, it's best to rotate the parity block of the sets between disks, i.e. evenly distribute parity blocks across the disks. (Note that having parity blocks without rotating parity is RAID 4).
- Striping data - typically, a strip of sequential blocks is placed on a disk before shifting to another disk in order to preserve the performance gains of sequential access (i.e. future reads/writes are likely to be sequential on a single disk, rather than having to switch disks between every block). Thus, rather than creating a set consisting of blocks and parity block, a set consists of data strips and parity strip! In other words, you can imagine that data striping treats the smallest unit as a sequential run of multiple blocks, known as a strip. Meanwhile, the set of data strips and parity strip is actually called a stripe.
Below is a diagram of RAID 5 in action.
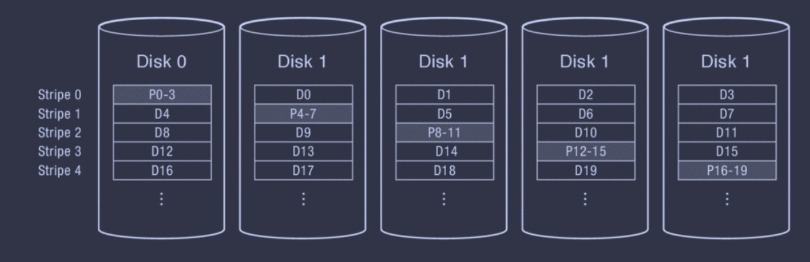
What if the system crashes while we're updating the parity block? Then, it'll seem like we have corrupted data, when really our update was just interrupted midway through. To deal with this, it's necessary to make our RAID updates atomic. There are a few solutions.
Non-volatile write buffer
Hardware RAID systems can often include a battery-backed write buffer, which simply includes the planned/in-progress writes.
Transactions
Transactions provide atomicity by nature.
Recovery scan
After a crash, the system scans the blocks and updates any inconsistent parity blocks.
Though we describe in detail just RAID 1 and RAID 5 above, there are actually many more RAID levels! The original paper described RAID 0 – RAID 5; three of these variants see wide use today.
RAID 0: JBOD (Just a Bunch Of Disks)
This system doesn't actually add any redundancy; it just spreads data across multiple disks.
RAID 1: Mirroring (described previously)
RAID 5: Rotating Parity (described previously)
More variants have also been developed.
RAID 6: Dual Redundancy
RAID 5 but with two parity blocks, generated using erasure codes (e.g. Reed-Solomon codes) that tolerate up to two disk failures.
RAID 10, RAID 50: Nested Raid
These were originally called RAID 1+0 and RAID 5+0. Quite simply, they just combine RAID 1 with RAID 0 or RAID 5 with RAID 0, respectively.
RAID Reliability?
So, how reliable are RAID 1 and RAID 5? They can actually lose data in 3 distinct ways.
- 2 full disk failures
- 1 full disk failure and 1+ sector failures on other disks
- Overlapping sector failures (same stripe) on multiple disks
The expected time until one such event occurs is the mean time to data loss (MTTDL).
But we can, of course, further improve RAID reliability. Broadly, there are three techniques.
- Increasing redundancy - double or even triple redundancy, i.e. mirroring data on more than one disk for RAID 1. A dual redundancy array allows data to be reconstructed tolerating at most two disk failures, i.e. this is just RAID 6, which is double redundancy for RAID 5.
- Reducing non-recoverable read error rates
Scrubbing - periodically reading all disk sectors, detecting sectors with unrecoverable read errors, reconstructing their contents with RAID, and remapping them to a spare.
More reliable disks - yeah... idk why this is listed in the textbook but yup - Reducing mean time to repair (MTTR)
Some systems include a hot spare disk that is idle, but can quickly replace a failing disk. MTTR is, though, inevitably limited by the time to write all the reconstructed data to the new disk too.
Some systems also decluster data, splitting the reconstruction across multiple disks to allow parallel reconstruction.
Software Integrity Checks
These are integrity checks implemented at the software/file system level, to detect hardware failures themselves. We discuss two common techniques.
- Block Integrity Metadata
This is commonly some sort of checksum included with each data block. For instance, the Write Anywhere File Layout (WAFL) file system stored a 64 byte data integrity segment (DIS) for each 4 KB block, which contained a checksum, the data block's identity, and a checksum of the DIS itself. - File System Fingerprints
File systems like ZFS include fingerprints that provide a checksum for the entire file system via a Merkle tree. Understanding a Merkle tree is left as an exercise to the reader... bonus points for studying its use in cryptography :)