Chapter 6: Multi-Object Synchronization
6.1 Multiprocessor Lock Performance
On a multiprocessor system, throughput may only be slightly faster than on a uniprocessor. This is typically a result of one of
- Locking. Exclusive access to data.
- Communication of shared data. Cache thrashing between processor caches, requiring communication of shared data between caches.
- False sharing. Due to the size of cache lines, there may two separate pieces of shared data in one cache line, inducing cache line bouncing between different processors when a piece of shared data is changed, despite not needing any communication.
Linux kernel locking evolution. Symmetric multiprocessing (SMP) was first added in version 2.0. To avoid concurrency issues, Linux added the Big Kernel Lock (BKL), which protected all shared data structures in the kernel. This allowed Linux to run on a multiprocessor machine, while more fine-grained SMP support was still being developed. As of version 2.6, the BKL is deprecated, and removed from most kernel subsystems.
6.2 Lock Design Patterns
Four design patterns
- Fine-Grained Locking. Partition object state into more fine-grained subsets, each with its own lock.
- Per-Processor Data Structures. Partition object state so most accesses are performed by threads on the same processor. This provides better hardware cache behavior, as it reduces the amount of communication between processors. However, the partitioning may result in decreased cache effectiveness, (e.g. distributed database cache, when machine X has a result cached and machine Y doesn't, and a request comes to machine Y).
- Ownership Design Pattern. Remove shared object from shared container on use to ensure mutually exclusive access. This works best when there is, e.g., queue of objects that must have work performed on each in stages.
- Staged Architecture. Divide system into multiple stages, so only threads within each stage can access that stage's shared data. This increases modularity, making it easier to reason about code, and improves cache locality for each thread. Note, however, that the processing in each stage must be expensive enough such that the cost of communication between stages is amortized. Also, staged architectures' throughput is limited by the throughput of the slowest stage, which can result in problems when a system is overloaded. (One solution is to dynamically allocate resources/threads to stages).
Commutative interface design. The UNIX open syscall API specifies that the syscall returns the next open file descriptor (ascending order). This forces open to use a lock, as two calls to open one after the other must return (or something similar in ascending order). A commutative API ensures that the result of two calls is the same regardless of which call was made first. For open, this would require returning any unique integer not currently associated with a file descriptor, and thus would not need a lock (outside of handling stdin, stdout).
6.3 Lock Contention
6.3.1 MCS Locks
The Mellor-Crummey-Scott (MCS) lock is an implementation of a spinlock optimized for the case when there are many waiting threads. On a multiprocessor system, acquiring and releasing a lock is associated with a much higher overhead, since the lock and shared data must be transferred between all waiting processors. Moreover, each thread attempting to acquire a lock queues an atomic RMW instruction, and the hardware has no way to know which one to prioritize (the release instruction!).
A naive solution is test and test-and-set. In essence, the spin lock is implemented as
while(lock == BUSY || test_and_set(&lock));
However, this doesn't help. The lock's release forces the previously holding processor to communicate the updated lock state to the waiting processors. This is an issue if a lock's critical section is typically short, as most time is spent on inter-processor communication.
A more scalable solution is to assign each thread its own memory location to spinlock on, and releasing the lock sets a bit for one thread's memory location, instead of letting all waiting threads know. Almost like a CV's signal instead of broadcast for spinlocks.
MCS is a popular implementation of this, that essentially maintains a queue of waiting threads. Waiting threads add themselves to the tail of the queue, and spin on the flag in its queue entry. The thread releasing the lock will set the flag for the first entry in the queue. This makes it much more efficient when there are many waiting threads, as the lock is passed efficiently along the threads in the queue. The overhead of the queue makes MCS less efficient with few waiting threads.
6.3.2 Read-Copy-Update (RCU) Locks
RCU locks are a read/write-lock that is highly optimized for read operations, while sacrificing write operations.
RCU makes three important changes to the standard RW lock:
- Restricted update. A writer thread publishes its changes to the shared data structure with a single atomic memory write. Typically, this is done by the writer thread (1) copying the data structure, (2) making changes, and (3) publish the corresponding pointer (by updating a shared location) to point to the new version.
- Multiple concurrent versions. There can be multiple versions of the shared data structure being read at one time. In essence, read-only critical sections can be reading different versions of the shared data structure, depending on when they started executing.
- Integration with thread scheduler. The RCU lock only frees an old version once it is confident no reader is still accessing it. Essentially, it waits until all readers accessing the version have released the read lock. The time between a new update being published and the last reader finishing is the grace period.
Some diagrams that demonstrate the idea:
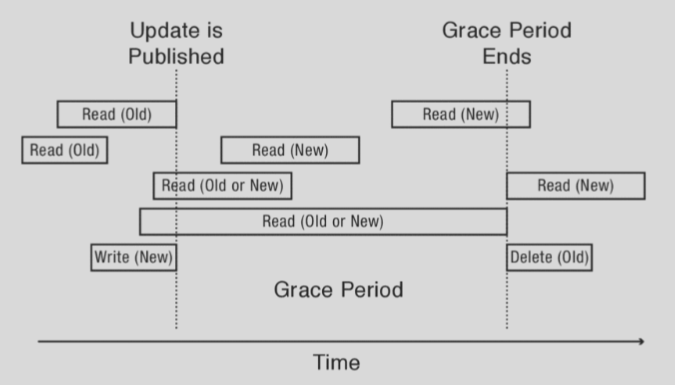
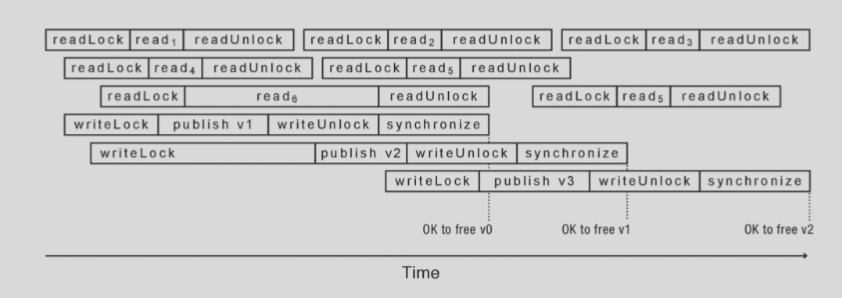
As you may notice from the second figure, writes must still be serialized. In particular, their publish phases must execute in order (otherwise, versioning would not be linear). However, any number of concurrent reads may occurs during a write.
The writers must also synchronize, i.e. wait until all readers are finished before freeing the previous version. To do this performantly, RCU locks often interface with the scheduler, where the scheduler has some function quiescentState() that informs the waiting writer that the old version is quiescent, i.e. no reader has access to it.
6.4 Multi-Object Atomicity
Sometimes, it is necessary for there to be concurrency-safe (essentially atomic) interactions between shared objects. There are some solutions to consider for this problem:
- Careful Class Design. Simply expose only APIs that allow concurrency-safe object interaction. This can make design more complex, however.
- Acquire-All/Release-All. A thread acquires/releases all locks associated with a set of operations/shared objects it must access for a critical section. This also adds serializability to programs, in which requests to different shared objects are guaranteed to be performed sequentially due to the locking mechanisms. However, this solution presents a problem—it's not always immediately obvious what locks are needed for each request.
- Two-Phase Locking. Two-phase locking involves acquiring only the locks necessary at each point. For instance,
f1needslock1andf2needslock2. In some cases,f1callsf2, in which caselock2is acquired later.
6.5 Deadlock
A deadlock is simply a waiting cycle among threads. The simplest example occurs in mutually recursive locking, i.e. thread 1 acquires A then B, while thread 2 acquires B then A. Another example is nested waiting, i.e. thread 1 acquires two locks, releases one with a call to a CV's wait, but other thread that will signal CV needs the other lock.
Deadlock vs. Starvation
Starvation: a thread fails to make progress for an indefinite period of time.
Deadlock: starvation, but no threads within a group can make progress ever.
There are four necessary conditions for deadlock.
- Bounded resources. There are a finite number of threads that can simultaneously use a shared resource.
- No preemption. Once a thread acquires a resource, its ownership cannot be revoked until it releases it.
- Wait while holding. A thread holds one resource (lock) while waiting for another. Also known as multiple independent requests.
- Circular waiting. Exactly what it sounds like.
Note, though, that these conditions are necessary but not sufficient for deadlock.
There are a number of ideas to help prevent deadlock.
- Exploit/limit program behavior. In other words, change program behavior to never satisfy one of the above conditions, e.g.
- Provide sufficient resources. For instance, threads often reserve space in the TCB for insertion into ready/waiting lists.
- Preempt resources. Allow runtime to forcibly reclaim thread resources.
- Release lock when calling out of module (i.e., a section protected by a lock). In other words, no nested locking.
- Lock ordering. Ensure locks are only ever acquired/released in the same order, whenever they are used. This prevents circular waiting/mutually recursive locking from ever occurring.
- Predict the future. If we know what threads may/will do, avoid deadlocking by waiting now.
- Detect and recover. Detect deadlocking, and restore a previous state.
6.5.4 Banker's Algorithm for Avoiding Deadlock
Banker's Algorithm is a procedure developed by Dijkstra that improves on the performance limitations of acquire-all. In the algorithm, a thread states its maximum resource requirements upon beginning a task, and acquires/releases resources incrementally as the task runs. Banker's algorithm uses this knowledge of each thread's maximum resource requirements to ensure that, if a request is added, all threads will eventually complete, via simulating the resource allocations. If a request comes in that would result in an unsafe state, i.e. could potentially lead to a deadlock, it will delay that request.
6.5.5 Detecting and Recovering from Deadlocks
There are two primary approaches:
-
Proceed without the resource. This is typically seen in systems where maintaining low latency is paramount. For instance, say a customer orders on Amazon, but some deadlock prevents the inventory from notifying the client of if the item is in stock. The client may simply give up, queue a check to be run later, and continue with normal web operations. If the item was in fact out of stock, the customer is notified later with an apology, rather than having the website hang.
-
Transactions. Intel Transactional Synchronization Extensions (TSX) are a good example. When deadlocks are detected, the thread (1) rollbacks to a clean state, (2) stops/rollbacks one or more victim threads, (3) lets other threads process, and (4) lets the victim threads finally complete. (Intel TSX actually does this slightly differently, allowing execution without any locking that rollbacks if any contention is detected). During a transaction, the results are not visible to any other thread; upon success, the transaction will commit its result, and the changes to the shared state will become visible.
One decision to make with transactions is which thread to abort. A suggested solution is wound wait, where the youngest transaction is aborted. This ensures liveness/avoids starvation, as eventually the oldest transaction will complete, and so on.
6.6 Non-Blocking Synchronization
In essence, non-blocking synchronization is the idea of writing concurrent programs entirely without locks. This eliminates lock contention and deadlocks, but can make programs much more complex and dangerous to design. In particular, wait-free data structures guarantees progress for every thread, regardless of other threads' states, while lock-free data structures guarantee progress for at least one thread. In essence, wait-free implies lock-free, and lock-free can cause starvation.
Aside: Handling Deadlocks
162 defines 4 ways of handling deadlocks:
- Denial. Pretend it doesn't exist. Applicable in situations where deadlock is rare and, in the case of a deadlock, the system can simply be restarted.
- Prevention. Write systems that don't satisfy all four deadlock conditions.
- Recovery. Let deadlocks happen, and recover from them.
- Avoidance. Dynamically delay resource requests so deadlock doesn't happen, e.g. Banker's algorithm.