Chapter 8: Address Translation
What does address translation enables us to do? Here's a list of a few...
- Process isolation
- IPC
- Shared code segments
- Program initialization (run program before loading all code into RAM)
- Efficient dynamic memory allocation
- Cache locality (via page coloring)
- Program debugging (via fine-grained memory permissions)
- Efficient I/O
- Memory mapped devices (map files into address space)
- Virtual memory (abstraction of more memory than physically available)
- Saving and restoring state
- Persistent data structures (even when programs/systems crash)
- Process migration (between servers)
- Information flow control
- Distributed shared memory
8.1 Address Translation Concept
Goals
- Memory protection.
- Memory sharing.
- Flexible memory placement. Ability to place process anywhere in physical memory.
- Sparse addresses. Allow each dynamic section to grow as needed.
- Runtime lookup efficiency. Fast hardware address translation.
- Compact translation tables. Small space overhead.
- Portability.
Process sees virtual addresses, hardware sees physical addresses. OS translates from virtual physical.
8.2 Flexible Address Translation
Base and Bound
The program memory must exist in the physical address range . In virtual address terms, this is . This method is simple and fast, but flawed. Dynamic memory regions are difficult since each program's memory must be continuous, and it only supports coarse-grained protections on the entire-process-level. Sharing is also extremely difficult.
Segmented Memory
This is a step up from Base and Bound, in which each segment of a process is assigned a base and bound. A virtual address is of the form , where the segment number indexes into a segment table. This also supports more fine-grained protections on a segment-by-segment basis. Process sharing of specific memory regions is also enabled by this scheme. However, this can be difficult for shared libraries, as processes load different numbers of shared libraries, and thus may assign different segment numbers for each library. This can be fixed via segment-local addresses for the library code (addresses relative to each segment).
Copy-on-Write
UNIX uses a copy-on-write mechanism for fork(), in which memory is only copied over when a parent or child process attempts to write to said memory. With the segmenting memory management scheme, this is now possible. The OS can mark the page as read-only in both the parent's and child's segment table, and then copy that entire segment. This extends to pages (which we'll discuss soon) as well.
Segments also allow for efficient dynamic memory allocations. In particular, when we allocate more physical memory for a segment, we want to zero the contents of the memory; otherwise, this may leak information from another process. However, we also want this to be efficient, and only zero memory if it will be used (just like how we only copy-on-write for fork()). The OS can address this via zero-on-reference: allocating a memory segment for, e.g., the heap, but only zeroing the first few KB and setting the bound of this segment to just the zeroed part. If the program expands the heap, the bound register can be increased and the additional memory can be zeroed before resuming execution.
However, segments have some major drawbacks. One is extensive external fragmentation. Managing a large number of variable size, dynamically growing memory segments naturally results in a distribution of memory with allocated and free segments scattered across. The system can then reach a point at which there is enough free space for a new segment, but the free space is not contiguous!
Moreover, it's difficult to know a priori how much a memory segment must grow. For instance, how much memory should the OS set aside for the heap? Too large of a segment wastes space, but too small and it's not possible to expand the heap without copying it elsewhere—which is extremely expensive. This is arguably the most principal limitation of segmentation.
Paged Memory
With paging, memory is allocated in fixed-size chunks called page frames. Address translation also works similarly to segmentation: virtual addresses are , and each page has its own access permissions. However, address translation functions slightly differently. The page number is used to index into the page table, which provides the physical page frame, i.e. the physical address is .
The most clear-cut advantage of paging over segmentation is the versatility for dynamically allocated regions. Now, it's not necessary to know a priori what size should be allocated for the heap, as the pages that form the heap do not need to be contiguous. Thus, whenever more space is needed, it suffices to simply allocate a new page from anywhere in physical memory! Notably, though, the virtual address space for the heap still appears linear to the program.
Sharing memory is also convenient; like segment tables, the corresponding page entry for each process's page table just needs to point to the same physical page frame. This does require what's known as a core map, which records information about each physical page frame, in order to reference count them.
The other optimizations that can be used with segmentation also apply. COW (copy-on-write) simply requires setting the page table entries to read-only, and specially handling them. ZOR (zero-on-reference) requires setting the top of each dynamically allocated memory region to be invalid, i.e. an attempt to access it traps into the kernel and subsequently allocates and zeros a new page only when needed.
Paging also allows running a program before all of its code and data is loaded. Initially, the pages are all marked invalid. Then, when the program attempts to access a page, it causes a page fault, which the OS handles to bring in the page from disk into main memory.
Data breakpoints can also be implemented with paging. Data breakpoints force a program to pause when it references/modifies a certain memory location. These are typically implemented with hardware support, but with paging, the OS can mark the page containing the relevant address as read-only, and check every single access. (This does, of course, have a much higher overhead than using hardware support).
There is one significant issue with paging, though. The page table scales proportionally to the virtual address space size. This means, with a 64-bit virtual address space and 4 KB pages, we'd need a page table of at least petabyte size! In general, the more sparse the virtual address space, the greater the space overhead of the page table.
It's possible to reduce the space overhead of the page table by choosing larger page frames. For instance, by using 4 MB pages instead of 4 KB pages, we reduce the space overhead of a 64-bit virtual address space page table to terabyte size. However, this can lead to significant internal fragmentation, in which space within each page frame is wasted, as a process may not need all the memory provided in the frame. Thus, there's a difficult tradeoff to be made between internal fragmentation and page table space overhead.
Multi-Level Translation
Is there a better way to deal with the massive space overhead of paging? Well, consider our problem: we want to perform a lookup on a sparse keyspace. There exist, in fact, several potential solutions. A tree or hash table might come to mind.
Multi-level address translation is precisely the application of trees to our problem. This system is very popular among modern systems, as they support several desirable properties that we've previously discussed, including
- Both coarse and fine-grained memory protection and sharing
- Flexible memory placement
- Efficient (dynamic) memory allocation
- Efficient key lookup for sparse address spaces
Practically all modern systems also use paging as the lowest level of the tree, and differ only in their method of reaching the leaves of the tree: segments plus paging, multiple levels of paging, or segments plus multiple levels of paging. Why is paging desired at the leaves of the tree? Well, beyond the previously described advantages of paging,
- Efficient memory allocation. By allocating physical memory in fixed-size page frames, management of free space is provided via just a bitmap.
- Efficient disk transfers. Hardware disks are partitioned into fixed-size regions called sectors, which must each be read/written in its entirety. By setting the page size to a multiple of the disk sector, transfers from disk are simplified.
- Efficient lookup. Using a translation lookaside buffer (TLB), we can make page translation lookups fast. Paging also allows lookup tables to be compact.
- Efficient reverse lookup. Fixed-size page frames make implementing the core map, which maps from a physical page frame to the virtual page, easy.
- Page-granularity protection and sharing. Coarse-grained and fine-grained sharing enabled by access permissions at each level of the tree.
Paged Segmentation
In paged segmentation, memory is segmented as usual. However, within the segment table, each entry actually points to a page table mapping the segment of memory. The entry's "bound" now describes the page table length, i.e. number of pagers. The virtual address is thus .
To keep the memory allocator simple, the maximum segment size is also typically chosen to ensure the page table for each segment can be mapped in only a few pages. For instance, for a 32-bit virtual address space and 4 KB pages, by using 10 bits for the segment number and 10 bits for the page number (the 12 other bits are used for the offset), the page table for each segment would fit exactly into one physical page frame, if each page table entry is 4 bytes.
Multi-Level Paging
Multi-level paging essentially extends paging to a tree-level structure. In x86-64, for instance, there are 5 levels of paging: Page Global Directory (PGD), Page 4th Level Directory (P4D), Page Upper Directory (PUD), Page Middle Directory (PMD), and Page Table Entry (PTE). In essence, an entry in the PGD points to a P4D, an entry in P4D points to a PUD, etc. (You can actually have directories point directly to PTEs for pages of larger size too—refer to hugepages in Linux for more details). Thus, the virtual address looks like
This structure enables us to allocate lower levels of the tree on-demand; only the top-level page table must be allocated in the beginning (and stored in the PDBR, page directory base register). Moreover, access permissions can be specified at each level, and so sharing at the granularity of page directories is possible too!
Multi-Level Paged Segmentation
This is just a combination of the above two parts! Memory is segmented, and each segment has a multi-level page table. x86 actually uses this scheme, with a per-process Global Descriptor Table that is simply a segment table, and a multi-level paging scheme similar to the previously described scheme, but with only 2 indices. (Notably, x86-64 largely forgoes segmenting, besides the FS and GS registers, and just uses multi-level paging as previously discussed). Like x86-64, the OS has a register for this top-level table: GDTR, global descriptor table register. x86 also keeps track of a segment register, which is used implicitly for relevant instructions.
Portability
The differences between translation mechanisms at the hardware level can make an operating system more or less portable to different processor architectures. Moreover, the operating system frequently needs to keep two records of address translation: one at the hardware level simply for address translation, and one at the software level to support COW, ZOR, and other features.
The software memory management data structures mirror the hardware structures, and consist of three parts.
- List of memory objects. Regardless of the underlying architecture's use of segmentation, the kernel memory manager needs to track which memory regions represent code, shared data, etc. Also, reference counts for COW.
- Virtual to physical translation. The kernel needs to track if an invalid page is really invalid, or just not loaded into the address space yet, or if a read-only page is truly read-only or just a COW page.
- Physical to virtual translation. That is, the core map. The kernel needs to keep track of all physical pages, and which processes map to each page, in order to update processes' page table entries when the physical page is switched out.
Regardless, though, operating systems must choose carefully how to structure their address translation mechanism to be portable to different architectures. Linux, for instance, has modeled its address translation methodology after the x86 architecture of segmented multi-level paging. This is great for porting Linux to x86, but makes it more difficult for ARM and other architectures. Meanwhile, Mach, and later Apple OS X, uses a hash table instead of a tree for software address translation. This is historically referred to as an inverted page table. This is not only more portable between different architectures, but using a hash table also speeds up translation, particularly as multi-level paging gains more and more levels to keep up with increasing memory.
Inverted Page Table
With an inverted page table, a table with size proportional to the number of physical page frames is kept. Virtual page numbers are the keys, and are hashed to find the corresponding physical page frame. Each hash table entry contains a tuple
Note the necessity of the virtual page number—this helps with handling hash table collisions, via chaining or rehashing or probing, and validating which physical page frame actually corresponds to this virtual page number.
A useful consequence of using this more portable hash table for software paging is that the hardware multi-level translation table can be treated as a hint, i.e. the result of a computation whose results may no longer be valid, but where using an invalid hint will trigger an exception. In particular, if the translations and permissions of the hardware page table are a subset of those of the software page table, it is a hint.
What about hardware hash tables? Do we still need multi-level page tables for our hardware? It turns out that, yes, it's still needed. The difficulty with hardware hash tables is that hash collisions become much harder to handle. If two pages hash to the same hash table entry, only one can be stored in the physical page frame; the other must be stored in a secondary hash table entry or even on disk. Copying in the new page can thus be expensive, especially if hash collisions are frequent. Moreover, hash tables tend to have worse cache locality. Thus, modern systems only use inverted page tables in software to improve portability.
8.3 Efficient Address Translation
There's just one issue; these hardware address translations involve multiple extra memory references per access to memory. That's a lot of overhead! Can we do this faster?
Translation Lookaside Buffer
Well, recall that we already have caches for all of our memory, to cache recently or frequently used data. We can apply the same idea here to produce the translation lookaside buffer (TLB), a cache for address translation.
The TLB simply maps previous address translations, with the following tuple for each entry
Exactly like the inverted page table, in fact! Though, instead of hashing, the TLB hardware checks all entries simultaneously against the virtual page number to find a match. If there's a match, we successfully have a TLB hit, and avoid the overhead of translating the address.
Of course, like hardware caches, the TLB is located in fast, on-chip static memory nearby the processor. Modern systems even include multi-level TLBs now, just like the popular multi-level cache design. This is expensive (cost-wise), but efficient and results in significant gains in processor performance.
A TLB also requires an address comparator for each entry to parallelize the search for a match. The TLB is, thus, frequently made set-associative to reduce the cost of the comparator; this results in slightly higher miss rates, but can reduce monetary costs significantly.
Software TLB?
You might wonder if we can have a software-loaded TLB as a fast path if the hardware TLB misses. This would also simplify kernel design, since it would no longer need to keep track of the hardware page tables. However, this requires the processor to trap into the kernel for the lookup; an expensive operation that can cost several hundred instructions. (While a TLB miss can be served by the hardware page table in an order of magnitude less instructions).
Superpages
There do exist some optimizations to improve TLB hit rate. For instance, kernels can implement superpages (a.k.a. hugepages). A superpage is essentially the result of having a PTE at a page directory higher in the page table hierarchy. For instance, with x86-64, with 4 KB pages, a PTE descending directly from a PUD might produce a 16 MB superpage. The benefit of this for the TLB is that a cached superpage will effectively cache address translations for more memory addresses!
Consistency
As with introducing a cache into any system, keeping cache consistency is always a challenge. There are typically three problems associated with TLB consistency.
-
Process context switch. On a process context switch, the page table switches. Thus, TLB entries become largely invalid. One approach to this problem is flushing the TLB, discarding its old contents. Flushing is somewhat expensive, though. Thus, another approach is using a tagged TLB, where each TLB entry includes the PID, and thus the hardware only considers entries that match the current process PID.
-
Permission reduction. When the kernel modifies a page table entry's permissions, hardware usually guarantees consistency with the processor's regular data cache of main memory; however, TLB consistency is typically not provided by hardware.
Why? There are a few reasons. (1) Page table entries can be shared between processes, so one modification can affect multiple TLB entries. (2) The TLB contains a virtual to physical page mapping, but does not record where this mapping information is stored (page table), so it actually can't tell if a write to memory would affect an entry. (And, even if it did track this, it would be inordinately expensive to check every single memory store to see if it affects a TLB entry).
Thus, the kernel is responsible for keeping the TLB consistent when permissions change. When permissions are added, the kernel actually doesn't need to do anything—any instructions that require the new permissions will cause an exception anyways, and force the kernel to load the updated page table entry.
However, after a permission reduction, the kernel must ensure the TLB is updated; otherwise, a memory access may be valid, according to the TLB, when said permissions have been revoked! (e.g., think COW). In these cases, it typically suffices to simply remove the entry from the TLB.
-
TLB Shootdown. On SMP (symmetric multiprocessor) systems, there are further complications. Each processor maintains its own TLB. Whenever a TLB entry is invalidated by any one processor, the TLBs of the other processors must be interrupted and updated as well. This is, of course, expensive, but certainly necessary, and is known as a TLB shootdown. In essence, the processor updating the TLB will send an interprocessor interrupt (IPI) to other processors, who will promptly update their own TLBs and acknowledge the original processor. Only then, after receiving acknowledgements from all processors, the original processor continues. Many kernels also batch TLB shootdown requests, since the overhead increases linearly with the number of processors.
Virtually Addressed Caches
We can further improve performance via virtually addressed caches. These are implemented in a small, on-chip cache, and cache contents of physical memory, but differ from normal hardware caches in that they are indexed by virtual address. Much like the TLB and normal hardware caches, the virtually addressed caches are frequently split into an instruction cache and data cache.
In essence, VACs are regular data caches, but with virtual address indexing. It also has the same consistency issues as TLBs do.
- Process context switch. Cache must be flushed or entries invalidated.
- Permission reduction. Cache must be flushed or the system must search and modify all affected entries, both of which are expensive operations.
- TLB shootdown. Again, same thing here.
Yet another issue, for VACs, is memory address aliasing. This is when processes sharing memory use different virtual addresses to refer to the same physical memory location. Each process would have its own TLB entry and VAC entries for this memory. If the memory is written to by one process, how does the system know to update the VAC to reflect this for the other copies (the entries for the other process)?
The most common solution to this is to store the physical address as well in the VAC. Then, in parallel with the virtual cache lookup, the TLB is consulted for physical address and page permissions. This is known as overlapping the VAC and TLB accesses, and results in more performant, consistent data retrievals. For store instructions, the system can also perform a reverse lookup in the VAC to find all entries that match the same physical address.
Physically Addressed Caches
And, finally, we've come full circle! On-chip (and typically multi-level) caches of main memory with physical addresses as indexes are included on all modern systems. These occur after a TLB/page table translation, and serve as a fast path before retrieving data from main memory. Critically, page tables are also frequently cached! This makes address translation, in the case of a TLB miss, even faster.
Diagram
Now, we can finally take a look at the complete diagram of, e.g., a load operation's process through hardware in efficiently retrieving data.
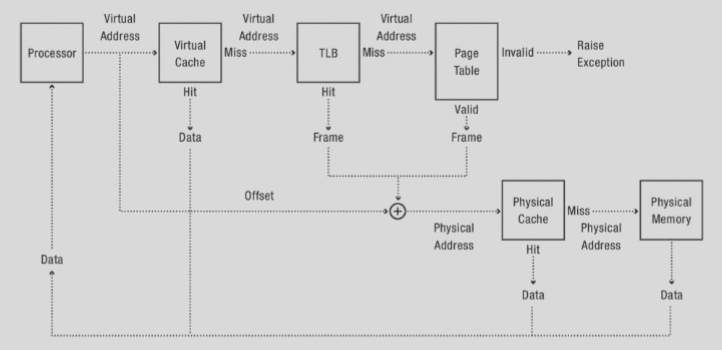
TLB Slice
This was briefly mentioned in the CS 162 slides. Essentially, since small TLBs are typically fully-associative, some TLBs have a very small, direct-mapped cache in front, known as a TLB slice, to speed up the most frequent TLB hits.
8.4 Software Protection
In this section, we consider software techniques to execute code in some restricted setting without relying on hardware address translation. But, why is this needed?
- Simplify hardware, increase portability.
- Application-level protection (e.g. web browser sandbox)
- Kernel-level protection (e.g. against third-party drivers)
- Portable security. Applications run across a variety of hardware devices and operating systems, and require a common runtime environment to isolate itself from these specifics. This includes downloading and running applications without concern of malicious application corruption.
Single Language Operating System
A very simple approach is to restrict all applications to be written in a single, carefully designed programming language. In particular, its language and environment should allow the kernel to enforce guardrails, and the compiler and runtime system should be trustworthy (and not require hardware protection).
One widely-used example of this is eBPF packet filters. The operating system allows users to load executable eBPF bytecode into the kernel to customize the kernel's network processing stack. The kernel restricts the packet filter language to make it easy to determine and permit only safe filters.
Another example is the use of JavaScript in modern web browsers. Browsers sandbox each website's JavaScript, preventing it from accessing other website data and the rest of the client machine. Yet another example is the Xerox Alto research machine, which exclusively used Mesa, and thus implemented all protection in software.
Language protection and garbage collection.
Garbage-collected languages must keep track of all valid pointers visible to the program. Thus, programs written in these languages cannot simply point to/jump to arbitrary memory locations; this would result in issues with implementing the garbage collector. Thus, a garbage-collected language necessitates software-level protective restrictions on the language's capabilities.
This, of course, has practical limitations though. Thus, on modern systems, this is typically combined with hardware protection.
For instance, using a single interpreted language seems safe; however, this requires trusting an interpreter and its runtime libraries. Interpreted code is also extremely slow, which forces interpreters to compile code to machine code and run directly on the processor, increasing the attack surface.
Thus, for instance, the Windows operating system runs web browsers in a special process with restricted permissions, to prevent a vulnerability in an interpreter or browser from potentially causing a host machine takeover.
Writing all software in a single, safe language is no good either. Defensive programming is still required at the trust boundary between application code and the operating system, and the compiler and shared libraries must be trusted.
Language-Independent Software Fault Isolation
Perhaps the most clear-cut limitation of a single-language system is, of course, the fact that programmers are limited to a single programming language. Of course, it's not possible for the operating system to trust the compiler of every programming language out there; is there a better way to efficiently isolate application code at the software-level without hardware support, and independently of the programming language?
This is especially important for systems that need nested levels of protection within a process: web browsers executing JavaScript in sandboxes, restricting kernel device drivers, etc.
It turns out that this idea of sandboxing code is a popular approach; both Google and Microsoft have developed sandboxes that safely and efficiently run code in any programming language. By validating all addresses accessed are within a restricted memory region, and using control/data flow analysis to remove checks (injected by the compiler) not strictly necessary for the sandbox to be correct, the execution of the process remains both safely isolated and efficient.
The control/data flow analysis can help optimize:
- Loop invariants. If a loop strides through memory, replacing many runtime checks with just one at the loop's beginning is much more performant.
- Return values. If the program provably never modifies the saved RIP on the stack, the return values don't need to be validated.
- Cross-procedure checks. If a parameter is always checked before being passed to a subroutine, it need not be checked inside the subroutine.
*Note that indirect branching and indirect accesses definitely need runtime checks, and thus are part of the checks that are still necessary for the correctness of the sandbox.
Virtual machines without kernel support.
We can emulate a VM without any kernel support by modifying the machine code of the guest OS. This includes changing instructions to enable/disable interrupts to no-ops, changing instructions to execute a user program to first sandbox the program separately, etc.
Sandboxes via Intermediate Code
For portability reasons, both Microsoft and Google generate intermediate code with their compilers, which are then sandboxed. This makes it much easier to modify code and perform flow analysis to enforce guardrails.
Notably, the Java Virtual Machine (JVM) is one similar example of a sandboxed environment. While only for Java, it converts Java into JVM bytecode that can be more easily verified at runtime for safety.