Which corresponds to essentially using the advantage with respect to the policy πθ, A^πθ, instead of the advantage with respect to the policy we're improving, A^πθ′. That is, leaving in the B term uses importance sampling to correct the advantage according to the importance sampling ratio between the two distributions; removing it means using the advantage without adjusting for the difference in distribution.
We also replaced term A with a state-action marginal, which is equivalent under expectation,
Policy gradient, notably, may be viewed as policy iteration.
Estimate A^π(st,at) for current policy π.
Use A^π to produce an improve policy π′.
We can formalize this by using an alternate objective
J(θ′)−J(θ)=Eτ∼pθ′(τ)[t∑γtAπθ(st,at)]
where we define
J(θ)=Eτ∼pθ(τ)[t∑γtr(st,at)]
we will attempt to prove this claim of equality.
Why do this?
Note that calculating the advantage Aπθ is easy—we use the estimator A^ we've constructed—while calculating the advantage Aπθ′ is hard, since we lack an estimator for the new policy.
The initial state distribution is the same for any policy.
Equivalent expression.
Equivalent expression (flips sign of second term, exploits ∞).
Definition of J(θ′).
Combining expectations (τ sampled from same distribution).
Definition of advantage function Aπθ.
So what does this really mean in the context of policy iteration? With the objective J(θ′)−J(θ), we are maximizing the expectation of our returns under policy πθ′, formulated via the estimated advantage, according to the advantage function of πθ, of the discounted trajectories sampled from πθ′.
where the inner expectation of sampling actions was changed to sample from the πθ′ distribution to the πθ distribution, with the added correction of the importance sampling factor πθ(at,st)πθ′(at,st). Thus, we've proved that using the advantage function of θ, not θ′, is okay! (The optimization of J(θ′)−J(θ) is the same as the optimization of J(θ′) by itself since J(θ) is a constant as the old policy's parameters θ are a constant).
because we'd like to sample from our θ distribution, and not have to generate new samples from our θ′ distribution. We will denote the RHS as Aˉ(θ′), and we will note that equality is generally not true unless pθ=pθ′; hence we want to show when exactly we may allow this approximation.
Claim: pθ(st)≈pθ′(st) when πθ≈πθ′, for some notion of "closeness" or ≈.
Naturally, such a claim seems obvious. We will proceed to formalize this notion, though
Proof. Case 1: πθ is deterministic.
Let at=πθ(st). Let πθ′≈πθ if πθ′(at=πθ(st)∣st)≤ϵ for some small ϵ. Actually, we can apply techniques from Lecture 2 to this proof; in particular, the proof about distributional shift for behavioral cloning. In fact, the rest of the proof is precisely identical! This allows us to conclude that DTV(pθ′,pθ)=21∑st∣pθ′(st)−pθ(st)∣≤ϵt.
This isn't quite a great bound yet, though, because the total variation divergence between the two distributions is linear in the horizon length.
Case 2: πθ is an arbitrary distribution (may be stochastic).
This is the more general case. Let πθ′≈πθ if DTV(πθ′(at∣st),πθ(at∣st))≤ϵ. We first consider a useful lemma:
If DTV(pX(x),pY(x))≤ϵ, there exists p(x,y) such that p(x)=pX(x), p(y)=pY(y), and p(x=y)=1−ϵ.
In other words, pX(x) "agrees" with pY(y) with probability 1−ϵ. In the context of our proof, πθ′(at∣st) takes a different action than πθ(at∣st) with probability at most ϵ. (In practice, we enforce this constraint).
This lemma actually allows us to do the exact same thing as before, i.e. show that DTV(pθ′,pθ)≤ϵt.
Finally, we'd like to relate the closeness between π's to the (bounds on) closeness between p's. We note that
pay close attention to the θ and θ′... they switch around a few times in the above sequence of equalities/inequalities. Note also that the last step is simply the application of the bound on the total variation divergence DTV.
where C=maxstf(st). Note the change from pθ′ to pθ in the outer expected value, i.e. sampling states from the distribution produced by πθ instead.
We'd like to find an upper bound, however, for the additional error ∑2ϵtC. We can note that Aπθ(st,at)=r(st,at)+γVπθ(st+1)−Vπθ(st). We can infer that γVπθ(st+1)−Vπθ(st) is likely pretty small! Therefore, r(st,at) is the largest contributor to Aπθ, and we can therefore conclude that we can reasonably bound Aπθ∈O(rmax). Subsequently, we can bound C∈O(Hrmax), where H is the horizon, due to the need to sum across the entire horizon of time steps. Furthermore, with discounting, we produce a geometric series that implies a bound of O(1−γrmax). Thus, we can bound ∑t2ϵtC∈O(ϵH21−γrmax). (Note the similarity to the bound derived in Lecture 2).
Notably, this is not a great bound at all! However, it does imply that, as ϵ shrinks, the error will become sufficiently small. In conclusion, it's okay to ignore the state distribution divergence provided we do not change the policy too much :)
Policy Gradient with Constraints
We'd like to limit the divergence between the two policies, πθ and πθ′, in our policy gradient algorithm.
We have a TVD upper bound on our state marginal difference. However, TVD, unfortunately, is inconvenient to work with due to its use of absolute values (which don't work well with logs and gradients). However, we can actually develop a bound on TVD in terms of KL divergence.
where DKL(p1(x)∥p2(x))=Ex∼p1(x)[logp2(x)p1(x)]≈∑ilogp1(xi)−logp2(xi). KL divergence has some very convenient properties that makes is easier to approximate. For our purposes,
where we can ignore the first term because it is not dependent on θ′. Thus, minimizing DKL is the exact same thing as maximizing the likelihood of samples from πθ(at∣st) (precisely like supervised learning).
Therefore, we can enforce this constraint by turning our constrained optimization problem into an unconstrained optimization problem. We write the Lagrangian
β←β+α(DKL(πθ(at∣st)∥πθ′(at∣st))−ε). (Intuitively, just adjust β depending on if the loss function is over- or under-constrained).
This is actually a form of dual gradient descent, which describes a general class of techniques to solve constrained optimization problems by alternating between (1) minimizing the Lagrangian over primal variables (θ′) via gradient descent and (2) taking a gradient ascent step on the dual variables (β). Also, for practical purposes, it's not necessary to wait for the first step to converge.
Rewriting in terms of our samples,
LKL(θ′,β)≈importance sampled surrogate objectivei=1∑Nt=1∑Hπθ(at(i)∣st(i))πθ′(at(i)∣st(i))At(i)(st(i),at(i))+penalty for moving away from samples of πθβlogπθ′(at(i)∣st(i))+const
And here's how the algorithm for PPO with KL divergence would look like.
since the importance sampling factor doesn't matter anymore when we're calculating w.r.t θ instead of θ′. This is just normal policy-gradient; so, to perform our first-order approximation, we can just substitute this expression in and then multiply by θ′−θ and then maximize over θ′, i.e.
θ′←θ′argmax∇θJ(θ)⊤(θ′−θ)
where J(θ) represents the normal policy gradient objective.
Can we just set θ←θ+α∇θJ(θ), then, for some constant α? Sadly, no. Even if we choose α=∥∇θJ(θ)∥2ε, which guarantees ∥θ−θ′∥2≤ε, this is not the same as our KL divergence constraint! This is because some parameters changes probabilities a lot more than others.
However, we can instead use a second-order Taylor approximation of the KL divergence, which comes out to
And now, with a first-order approximation of our objective, and a second-order approximation of our constraints, this becomes a (tractable) quadratic programming problem.
tip
The comparison between the constraint ∥θ−θ′∥2≤ε and the second-order approximation of the KL divergence may be likened to a sphere vs an ellipsoid in hyperdimensional space, where the latter essentially adjusts according to the "strength" or "impact" of a parameter on the divergence.
With this, we can define our gradient ascent to be
θ′α←θ+αF−1∇θJ(θ)=∇θJ(θ)⊤F∇θJ(θ)2ε
This is known as the natural gradient.
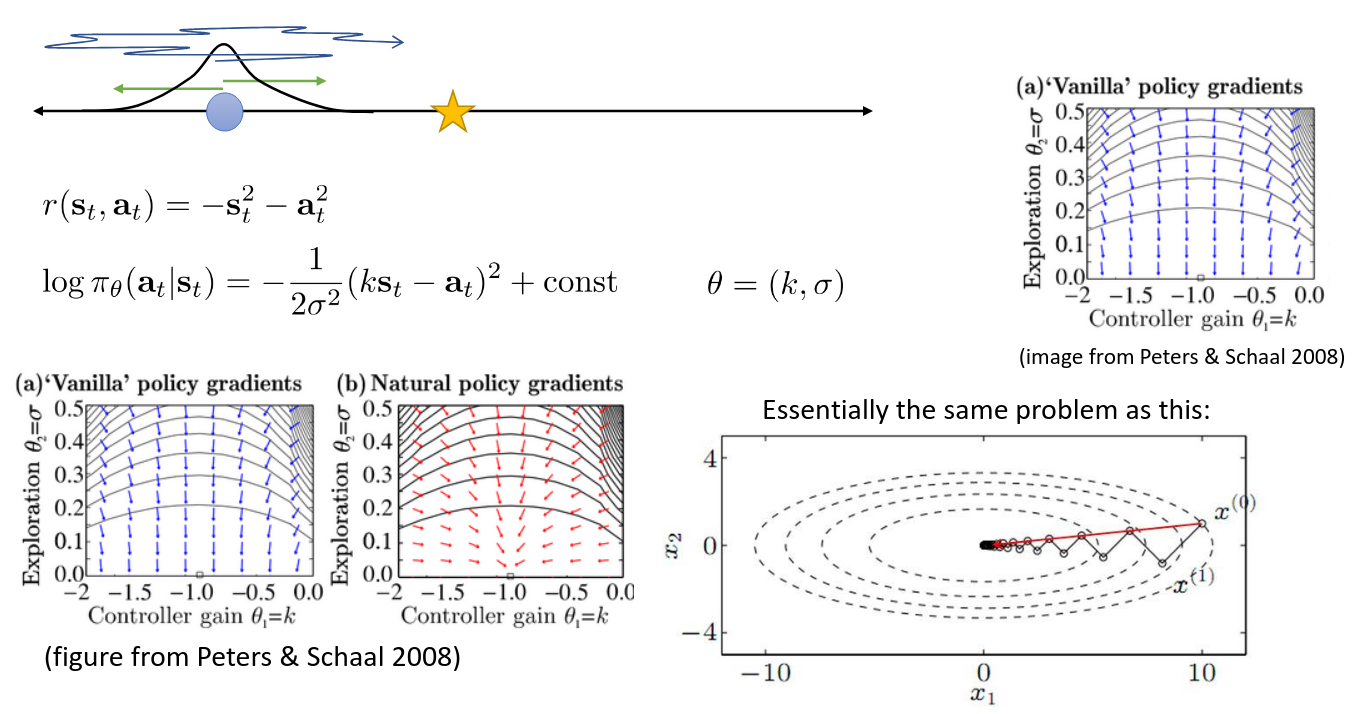
But what's the point of the natural gradient? The idea is that naive gradient ascent experiences problems due to poorly-conditioned functions (see this section from Goodfellow's Deep Learning). See the slide below.
where F≈N1∑i=1N∑t=1H∇θlogπθ(at(i)∣st(i))∇θπθ(at(i)∣st(i))⊤.
warning
In practice, building the full matrix F and calculating its inverse is far too expensive (quadratic in the number of parameters). Instead, conjugate gradient is typically used. (See here). The TL;DR idea is that you'll only ever use F−1 to perform matrix-vector multiplication.
Conclusion
Policy gradient is more productively interpreted as a form of policy iteration.
PPO with clipping is a heuristic approximation of PPO with KL.
There are other ways to enforce the constraints
Natural gradient!
TRPO vs PPO? Usually PPO today due to ease of implementation.
Note that TRPO/natural gradient was the precursor to PPO with KL divergence, i.e. PPO is a refinement that offers lower implementation complexity and lower computational complexity.