Lecture 12: Variational Inference in RL
Amortized Variational Inference
The problem with variational inference, as mentioned at the end of last lecture, is that there are far too many parameters to tractably train. So, how can we resolve this?
Recall that . A naive solution might use only one unified function for all data points, rather than a function for each individual data point. This produces a valid lower bound, but... this is probably a terrible lower bound since it's highly unlikely every data point has the same posterior (and if so, your dataset probably isn't good anyways!).
A better solution is to represent all with a function (neural network) such that , i.e. it produces a distribution over for each distinct . For instance, we could use a function , where the neural network's parameters are and are functions that output the posterior's mean and variance given a data point as input.
Notably, our update step for doesn't really change; now, we simply update to maximize when training on data point .
This is known as amortized variational inference, because the difficulty of computing the posterior distribution is "amortized" or distributed across all the data points (rather than determining a posterior for each data point). Our algorithm thus becomes
-
For each /mini-batch
- Sample and calculate .
- .
- .
where the loss function for data point is
Now let's define . Then this becomes
...hang on, doesn't this look like the expected reward function for an RL problem now? That is, is precisely an expected reward function for a "policy" . This means we can apply RL methods for optimization—in particular, we can just use policy gradient!
Applying policy gradient, we can derive a way to determine with samples.
and this leads to
so we can now compute our gradient on w.r.t via sampling! (Note that computing is well-known).
But, this gradient has one problem—it's a very high variance gradient. Can we do better?
Reparametrization Trick
Consider that, if , we can express samples of as simply where . Notably, this expression is independent of . This allows us to then rewrite
In other words, we have reparametrized the expectation under into an expectation under a constant distribution . Then, to estimate , we can sample instead (usually just one ), and then just perform normal backpropagation because doesn't depend on .
This results in a much lower variance estimator.
Why is this possible here, but not for normal RL? In our normal policy-gradient, is unknown; it's a function of environment dynamics that we do not assume knowledge of. However, here, we defined and know the expression for ; therefore, we can compute the gradient of , and therefore backpropagate gradients through .
Me too. I read this blog (and asked Google/Gemini) to try and understand why. From my limited understanding, it's because we cannot backpropagate through the actual sampling of from (due to the stochasticity of sampling). This is problematic because, in standard variational inference, we are trying to compute a gradient w.r.t over an expectation over a distribution parameterized by . We'd like to estimate the expression via Monte Carlo sampling; to do so, we need to push the gradient operator inside the expectation. However, this is mathematically incorrect—the distribution we are taking the expectation over is parametrized by itself. Thus, a single sample does not actually convey any information about the gradient w.r.t , because it carries no information about the distribution . Without reparametrization, we can use the policy gradient/REINFORCE trick to rewrite the expectation as ; this is what we did previously. However, this suffers from high variance because it ignores the gradient of itself. The reparametrization trick helps us rewrite the expression, turning a gradient of an expectation into an expectation of a gradient. By defining , we can write , which allows us to push the gradient operator inside the expectation (since is unrelated to ), turning the expression into . This gradient now actually uses the gradient of our relevant loss function , yielding lower variance and consequently faster convergence.
Implementation
We can turn into an equivalent, but more useful, expression for implementation.
As and are both Gaussians, the KL divergence between the two has a nice analytical form. Meanwhile, the gradient of the term on the left may be estimated via Monte Carlo methods, as explained above.
Notably, the resulting architecture is precisely a variational autoencoder (VAE). The encoder network, parametrized by , takes an input and produces and . With the random sampling of some noise , we produce . This is then fed into the decoder network, parameterized by , to produce . Training is done by backpropagating through the entire computation graph just described for each minibatch of samples. (With the addition of the KL divergence, of course, to the loss function; this may be represented analytically, though, and thus its gradient may be computed without backpropagation).
So what's the intuition behind this? This KL divergence term tries to keep the closer to the prior , while the other term tries to ensure the is good enough such that may reconstruct (decode) the original from the encoded . With the selection of a simple prior, this usually means that the VAE is looking for the simplest that still does a good job of reconstructing (i.e. encodes a simple representation with only the most important information critical to reconstructing ).
Reparametrization Trick vs Policy Gradient
Policy gradient
- Can handle both discrete and continuous latent variables
- High variance
Reparameterization trick
- Only continuous latent variables
- Simple to implement
- Low variance
Generative Models
Variational Autoencoder
First up, the VAE. As aforementioned, it's precisely what we defined above. We have an encoder and a decoder . Refer to above for a more detailed explanation on its training.
Note that we may sample (generate ) from the VAE by first sampling and then sampling . Notably, we sample from the prior , not the learned posterior , as we are generating and therefore do not have access to . However, this is okay because our KL divergence term ensured that , and therefore the distribution of 's seen during training are approximately similar to the distribution of 's seen at test/inference time.
Representation Learning
We can train a VAE to learn a latent variable that is a representation of a state . Then, during training, rather than train our policy to learn off of states as inputs, we use the latent space of the VAE instead of our state space! That is,
- Train VAE on states in replay buffer .
- Run RL using as the state instead of .
This is nice because the latent variables are much simpler than the possible states, and the subspaces of the latent space may represent the underlying factors of variation within the state space.
Conditional Models
We can modify our loss function to be
this is useful for, say, modeling our policy, i.e. we predict our actions given the state and the latent variable , which really represents the different modes of the action distribution (peaks).
This may be used for multimodal imitation learning, since represents the different modes of the action distribution, i.e. can be interpreted as a variable of a "latent action suggestion" space.
Relationship to Diffusion and Flow Matching
The below slide summarizes the idea.

where diffusion is a step-by-step VAE that uses the noising process as its encoder and the denoising process as its prior.
State Space Models
Again, we'll discuss this more when we talk about model-based RL. In essence, though, with a partially-observed RL problem, we use a VAE that almost acts like a recurrent neural network through time steps, i.e. we learn . The prior is much more complicated, i.e. , the decoder is . and the encoder is . Notably, we have much more freedom of choice with regards to the model for the encoder.
Control as Inference
Imagine trying to train optimal control by modeling human behavior. If we assume humans are perfectly rational, and take actions to maximize some implicit reward function, then this works fine! Unfortunately, humans, and organisms in general, do not exhibit perfect rationality, and therefore do not perform optimal actions.
For example, consider a monkey trying to move an object from one place to another. Typically, the monkey won't follow a perfect, straight-line path; there will be some imperfections. But, crucially, it will allow some certain degree of mistakes or approximation of optimality such that it will still achieve the objective. Thus, the monkey exhibits approximate rationality and includes some stochastic behavior, but in places where it doesn't really matter—the key lesson here is that some mistakes are more important than others!
Thus, when we're modeling, say, human behavior, we shouldn't model some perfect reward maximization algorithm to produce optimal behavior; instead, we should model how humans act approximately optimal, or model the human "intention" of acting optimal.
We can add a binary variable at each time step of a trajectory, where denotes a monkey exhibiting the intent of optimal behavior and represents the opposite. (In other problems, may take on a wider range of values). And, we will define , where so that is a valid probability distribution. We will see why this is helpful soon.
Now, consider , which represents the probability of trajectory given that the monkey is trying to be optimal throughout the entire trajectory.
this seems pretty intuitive! As the reward of a trajectory increases, the probability of it occurring under optimal monkey behavior increases too. And, critically, we can see how this probabilistic model can assign nonzero probabilities to potentially suboptimal trajectories that are "close enough" to optimal.
This is important because such a model can help us ignore noise in samples of human or otherwise approximately optimal behavior. It's very applicable to control and planning problems, and, in some sense, can provide an intuitive explanation for the benefits of stochasticity.
Now, what sort of relevant inference problems do we care about?
- Computing backward messages , i.e. "how likely will the monkey continue to be optimal for the rest of the episode given the current state and action?"
- Computing the policy , i.e. "how likely is an action given a state and the assumption that the monkey is optimal over the entire trajectory?"
- Computing forward messages , i.e. "how likely is state given the assumption that the monkey was optimal over all previous steps?"
The key idea here is that backward messages will help us compute a policy, while forward messages will help us figure out the state the monkey ends up in.
Backward Messages
Note first that we know . So, we'd like to compute a recursive formula backwards through time, using the last time step as our base case.
Note the use of the Markov property in the second step. Also, note that is a prior for our actions, and represents the monkey's actions under zero optimality conditions—this can essentially be assumed to be a uniform distribution and thus ignored, and we will formalize why soon. The above derivation allows us to write
and we can iterate from to to compute all values.
Now, let's define
has recursive definition
We will call a soft max.
This is not the same thing as a softmax!!
Why is called a soft max? Because is dominated by large , and thus this is a continuous function that approximates the maximum value of . Formally,
Meanwhile, has the following recursive definition
If state transitions are deterministic, the recursive formula has the form
which looks exactly like our usual -function Bellman update equation, in fact!
Now, with deterministic transitions, if we just throw these functions into value iteration, we get essentially the same thing, except now with our "soft max" function replacing the usual "hard max." But, without deterministic transitions, there's now also a "soft max" function over the possible state transitions; in other words, this encourages excessive optimism, in which the algorithm favors states that may lead to potentially higher-value states, but may also have fairly high probability of low-value states. (Since it takes the expected value of the soft max over the possible next states!). This is pretty bad... but we'll come back to this in future lectures.
Action Prior
Let's now return to the action prior . Previously, we just assumed that it was a uniform distribution, but this may not always be the case. (In our monkey example, the monkey might prefer small movement actions because it's lazy). If it isn't uniform, then our recursive definitions change a bit.
Or, we could simply define a new function
and define as
In other words, we can treat the action prior as simply modifying the reward function to be ! And, hopefully, this should intuitively make sense; a monkey that is lazy in his action prior would, in its perspective, be receiving higher rewards for lazier actions. Now, this mathematical basis actually gives us reason to assume the action prior is simply uniform henceforth; even if it isn't, we can simply modify the reward function to express it.
Policy Computation
Now, we can finally compute our policy using our backward messages.
where the steps are
- Definition
- Due to the Markov property, captures all that is needed for the previous states; therefore, only the future optimality variables are needed.
- Law of Conditional Probability
- Bayes' Rule + Law of Conditional Probability
- Law of Conditional Probability
The final formula is notably the same as
where the action prior doesn't matter for the reasons given above. Thus, we have a formula for our policy in terms of our backward messages! But what does this mean? Well, if we replace here with and , we find that
Intuitively, this formula says that our policy is just more likely to take the actions that provide higher advantages. (This is effectively analogous to Boltzmann exploration, which was briefly mentioned towards the end of Lecture 7).
Larger reward functions result in sharper policies, so oftentimes a temperature constant is applied, . As temperature decreases, the soft max approaches the hard max function, and the policy approaches a greedy policy.
Forward Messages
We won't discuss the math in detail, but the whole idea and simplification is very similar to the derivation of backward messages. The key point is, though, is that once we have derived the forward messages recursive formula (allowing us to compute the forward messages across an entire trajectory), we can then compute the probability of any state along an optimal trajectory. In fact,
and, one may note
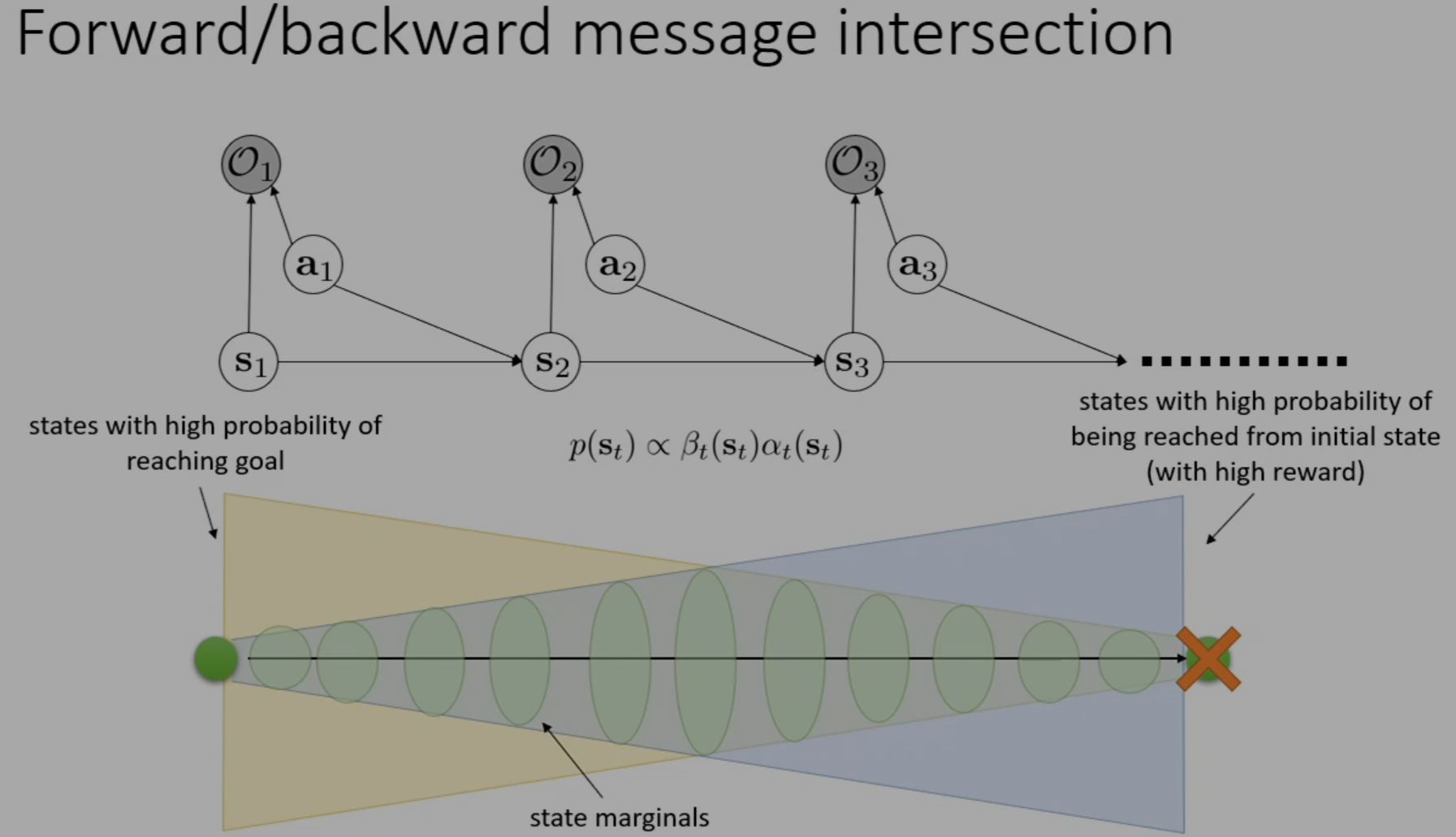
In other words, there is more variability in the middle of the trajectory, and less towards the start and the end of the trajectory. Perhaps intuitive, but now we've formalized this idea :)