recall that, with stochastic environment dynamics, the second term of the Q-function expression encourages excessive optimism regarding states with very large rewards/values, even if they occur with very small state transition probabilities. We'd like to eliminate this excessive optimism.
Let's first take a step back and consider: why does this occur in the first place?
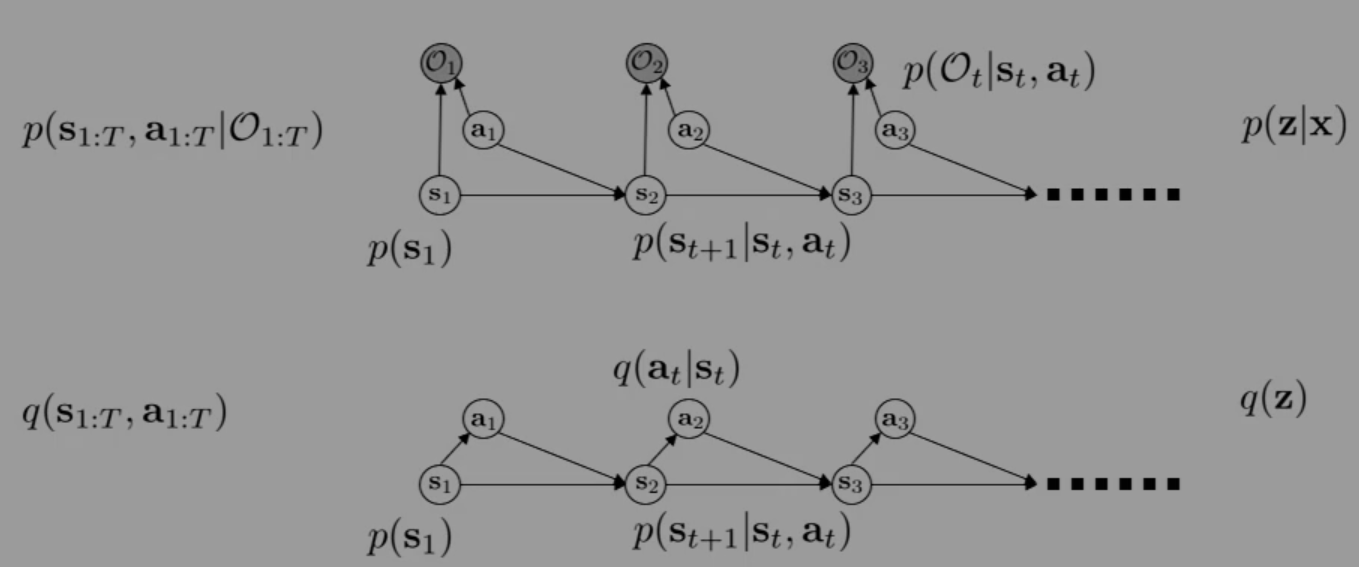
Our inference problem is p(s1:T,a1:T∣O1:T), i.e. what is the probability of the trajectory τ given that the monkey is being optimal? Through marginalization over the time steps t and conditioning on the state st, we produce the policy p(at∣st,O1:T), i.e. what is the probability of the action at being chosen in state st given the optimality of the monkey? However, we may note that Ot is really just an indicator (evidence) of whether or not at was high reward or not; thus, this is really asking, "given that you obtained high reward, what was your action probability?" This, intuitively, is a good question to ask—after understanding that we obtained a high reward, we'd like to maximize our action probability for this high reward.
However, when performing inference over the computational graph, the action probabilities are not the only factors; critically, the state transition probabilities are involved too. In fact, we can similarly marginalize over t and condition to produce p(st+1∣st,at,O1:T)=p(st+1∣st,at). That is, "given that you obtained high reward, what was your transition probability?" And this is a bad question to ask! This is like, say, training our model to make a decision on whether or not to buy a lottery ticket after they already observed winning the lottery ticket in the future. However, just because it won this time does not mean that buying a lottery ticket is a good action in general—in essence, the model is learning action optimality from the fact that it "lucked out" from hitting rare state transition probabilities, and believes it can optimize this state transition probability to always happen.
Still confused?
Courtesy of Gemini, who clarified the lecture's idea for me. As you noted, standard inference asks: "Given that I succeeded, what must have happened?" If you condition a probabilistic graphical model on achieving high reward (O1:T=1), the model uses Bayes' rule to update the probability of all latent variables that caused that reward. Because both the actions at and the state transitions st+1 are latent variables leading to the reward, the model updates both.
This leads to the model becoming "delusional." If it is in a stochastic environment where taking a risky action usually results in death but has a 1% chance of hitting a jackpot, standard inference looks at the jackpot and assumes the 1% chance is actually a certainty. It essentially assumes it can control the environment's dice rolls.
In short, we'd like to phrase the question as "given that you obtained high reward, what was your action probability, given that your transition probability did not change?" More generally, we'd like to find a way to tell the model to maximize the probability of success without changing the environment dynamics. Or, mathematically, we'd like to find another distribution q(s1:T,a1:T) that is close to the posterior p(s1:T,a1:T∣O1:T) but has static dynamics p(st+1∣st,at) (i.e. the model should not believe it is capable of maximizing state transition probabilities like action probabilities).
Well, we can actually apply variational inference to this problem! Let our observed variables be x=O1:T and our latent variables be z=(s1:T,a1:T). We'd like to find a q(z) that approximates p(z∣x); in particular, we will choose to define
Notably, it's very unusual to include p(s1) and p(st+1∣st,at) in the definition of q, as, in variational inference, it's typically desirable to make q a simple distribution (for a tractable approximation), and we have no guarantees about the simplicity of those distributions derived from the computational graph. We will immediately see why this is useful, though (induces a lot of cancellation below).
Then, according to the ELBO (evidence lower bound)
This looks pretty similar to what we've seen before; in fact, it's just our regular RL policy gradient objective plus the entropy of the action distribution! Crucially, though, the only thing within the expectation that is not fixed relative to q (since the expectation is computed over q) is the action probabilities! Our choice to hardcode the environment dynamics p(st) and p(st+1∣st,at) into q(τ) cancels with the existing probabilities in p(τ,O1:T). Thus, our model won't try and modify our state transition probabilities to maximize p(O1:T); it's forced to optimize only q(at∣st), which is the only aspect the model actually controls.
Just one final note to close this off: we still need to solve for q(at∣st) for all t. We can recurse backwards, like we did for backwards messages. We first compute the base case
Various modifications like discounting and temperature may also be added.
Maximum Entropy RL Algorithms
Why use soft max?
The easy answer is that it encourages more exploration, though this does not capture the entire impact of the soft max. The true answer is that it encourages robustness to inaccurately specified MDPs, i.e. the addition of the entropy term H(q) encourages the model to seek high rewards while acting as randomly as possible, eventually placing the learned policy in an action space that is robust to perturbations. In reality, though, the real answer is that it just works well in practice ;)
Q-Learning with soft optimality
Standard Q-learning uses the hard max over the Q values to determine the value function, i.e. V(s′)=maxa′Qϕ(s′,a′). For soft Q-learning, we just change the hard max to soft max. Ultimately, this not a very popular algorithm because, for small action spaces, the hard max works just fine.
Policy Gradient with soft optimality
Recall that the control with variational inference strategy ended up with a policy gradient objective with an added action entropy term. The modification to policy gradient is precisely the same, just define J(θ)=∑tE(st,at)∼πθ[r(st,at)+H(πθ(at∣st))]. This is very commonly applied, because it's simple to add (entropy usually has a closed form expression for most policy classes) and policy gradient often collapses to a deterministic, non-exploratory policy too soon during training.
Soft Actor-Critic
This is the most well-known application of soft optimality. We modify two things:
where you may recall that the yi are the target values used to train the critic Q^ϕπ. Note that, conventionally, the entropy for the Q-function is usually estimated, i.e.
Also, it's very common to add a "temperature" β as a coefficient to the entropy terms.
Inverse Reinforcement Learning
In standard imitation learning, e.g. behavioral cloning, the model attempts to copy the actions the expert takes, without any reasoning about the action outcomes. In contrast, humans, when learning, attempt to copy the intent of the expert, and consequently may take very different actions due to their reasoning about the expert's intent. Thus, it's potentially very useful to learn reward functions from demonstrations, rather than have the developer define a reward function for the model to optimize.
Our previous soft optimality or control as inference framework is very helpful for this. Let's use the same probabilistic model with the same optimality variable; but now, instead of learning a policy based on a reward function, we will attempt to learn a reward function given trajectories sampled from a soft-optimal policy. In other words, we have
p(Ot∣st,at,ψ)=exp(rψ(st,at))
and consequently
p(τ∣O1:T,ψ)∝p(τ)exp(t∑rψ(st,at))
Note that there's a hidden denominator involved with the expression as well that's not shown in the proportionality equation. In particular, the denominator is Z, the partition function Z=∫p(τ)exp(rψ(τ))dτ.
Maximum likelihood learning tells us that the optimal ψ is simply
ψ^=ψargmaxN1i=1∑Nlogp(τi∣O1:T,ψ)
Also, we may note that, when taking the gradient of p(τ∣O1:T,ψ) w.r.t ψ, p(τ) is irrelevant since it represents the environment dynamics and is thus independent of the reward parameters. Therefore, we're really considering
L=N1i=1∑Nrψ(τi)−normalizerlogZ
where logZ shows up due to the hidden Z denominator, as aforementioned.
Notably, the gradient is zero when π∗(τ), the policy of our expert that we estimate with samples, is equivalent to p(τ∣O1:T,ψ), the soft optimal policy produced by following our current estimated reward function.
Additionally, because the partition function Z integrates over all possible trajectories, it is of course intractable to compute directly. Therefore, we must estimate it instead—we can use variational inference, which dictates that we should train a maximum entropy RL agent to approximate the intractable optimal policy for the current reward function rψ. Only then may we sample from this policy to produce trajectories τ for the second term Eτ∼p(τ∣O1:T,ψ)[∇ψrψ(τ)].