Lecture 14: RL with Sequences and LLMs
Reward Learning and Inverse RL
Recall the idea of inverse reinforcement learning (IRL): learning a model of the reward function demonstrated through some samples from an "expert" actor. This is in contrast to behavioral cloning in imitation learning, which simply seeks to mimic the behavior of the expert, and therefore expresses limited generalization to unseen states that require similar reasoning. (There are also other advantages of IRL, such as a lack of the compounding error from distributional shift that behavioral cloning typically encounters).
When we attempt to apply inverse RL to our previous soft optimality framework, we attempt to learn the reward model, provided we have sample trajectories from a soft-optimal policy. We use the equation
and use maximum likelihood estimation to find that
where is the inverse RL partition function, and is equivalent to
Note that functions as a "normalizer" for in order to produce a probability distribution, considering that the rewards themselves are unnormalized. Taking the gradient of our loss function, we find that
In words, these expectations are over trajectories produced by the...
For estimating that second expectation, i.e. the expectation over trajectories from our soft optimal policy, we can apply any maximum-entropy RL algorithm (see Lecture 13). Thus, we can just do
Unfortunately, this method is computationally expensive. (Why? We effectively have two nested loops of gradient ascent; for every step we take on , we have to run an entire maximum-entropy RL algorithm to relearn our soft optimal policy). So, can we do better?
Taking ideas from generalized policy iteration, we can be "lazy" with our relearning of our soft optimal policy; instead of learning an estimate of until convergence every time we update , we only make a marginal update (take a few policy gradient/max-entropy algorithm steps on our policy ) that brings us closer to the soft optimal policy for our new reward function. Sadly, this is not valid and produces a biased estimate—our second expectation is now being performed over samples taken from a non-optimal policy for our reward function...
...wait. Training on samples taken from a trajectory distribution produced by another policy? Isn't that just off-policy learning? So we can just use importance sampling to correct our algorithm!
where we define
intuitively, this just weights samples according to their reward, computed by the current reward function, relative to the probability of the sample occurring under the non-optimal policy. In other words, reweighting the samples to more heavily favor those that the optimal policy of the current reward function would have been more likely to take.
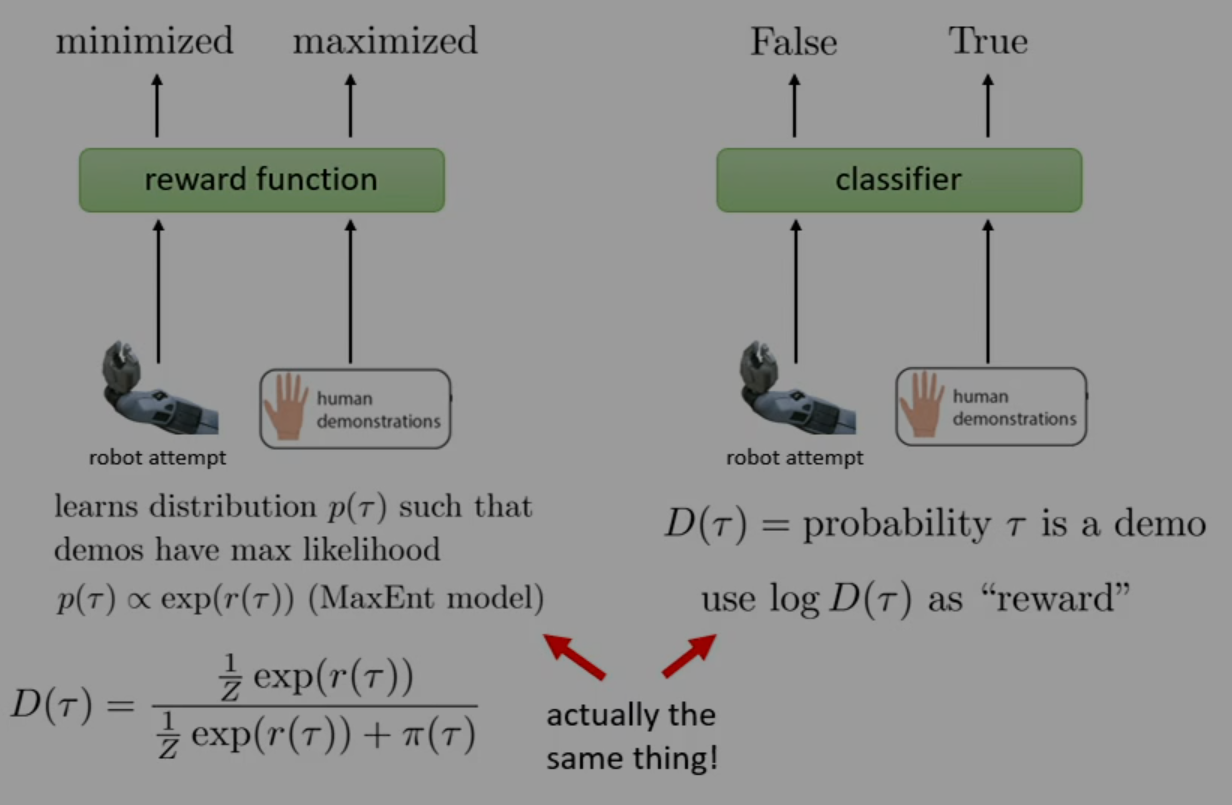
One may interpret this training procedure as a two-player adversarial game. There is a discriminator, , that attempts to increase the likelihood of samples from the expert demonstrations (positive first expectation encourages gradient ascent on/maximization of rewards from the expert trajectories), and simultaneously decreases the likelihood of samples from the policy (negative second expectation encourages gradient descent on/minimization of rewards from policy trajectories). Meanwhile, the generator is continuously improved to make it harder for to distinguish between samples from the expert and samples from . In this way, we continually improve our reward function and policy in a competing manner, until convergence at an equilibrium where the , i.e. the policy is encouraged to imitate the expert.
Such game-like models are known as generative adversarial networks (GANs). A discriminator model is trained to distinguish between samples from a dataset and samples from a generator model, while the generator model is optimized to fool the discriminator.
So, let's go back and approach this question from the beginning, but with the intent of designing a GAN for our problem. We still have a policy as our generator model, but instead of a reward model, we'll use a binary discriminator.
and our policy gradient is
This is much simpler to implement than our inverse RL algorithm. However, at the end of training, since the policy is essentially identical to the expert demonstrations, the discriminator will learn to simply output probability on every input; that is, the discriminator knows nothing at convergence! Moreover, it's generally not possible to reoptimize the reward function .
In short, though, we have the following comparison.
RL and LLMs: The Basics
Important questions for applying RL to LLMs:
- What is the (PO)MDP, i.e. (partially observed) Markov decision process?
- What is the reward function?
- What algorithm do we use?
First, we discuss a short anatomy of LLM training.
-
Pre-training: Supervised training on a large corpus of data, gives LLM knowledge.
-
Post-training: Tells LLM how to use its knowledge.
- Supervised fine-tuning (SFT) (instruction tuning, basically imitation learning) on a smaller, high-quality dataset that demonstrates what you want the LLM to do (e.g. be a helpful model).
- RL fine-tuning (e.g. reinforcement learning from human feedback/RLHF).
Instruction tuning was the initial LLM post-training methodology. However, it's labor-intensive to collect an SFT dataset, especially for skilled tasks like programming. Reinforcement learning offers a more tractable solution.
There are two main approaches to RL post-training.
- Training an LLM to appeal to human preferences. This can be dangerous, though, if preferences do not actually reflect what's desirable (e.g. LLM removes all test cases to pass all unit tests).
- Training an LLM to be correct. (a.k.a. RL from verifiers). Typically, "thinking mode" is a product of this. This is difficult to check objectively, however.
So how do we define our MDP for an LLM? There are a couple methods.
- Define where is the response and is the prompt, i.e. creating a one-step MDP.
- Define for all tokens in the response, where is the next token and is the prompt and all the tokens of the response so far, i.e. creating a multi-step MDP.
The second perspective is more sensible, as it allows for intermediate rewards (rewards during response generation) and value function baselines (which tokens are better than others?).
We'll now try and apply policy gradient to LLM post-training. We have, as usual,
where the first approximation is a REINFORCE-style estimator and the second approximation is an importance-weighted estimator like PPO. In practice, the second approximation is used for efficiency reasons (multiple gradient steps for each data sampling step).
Algorithms for RL with LLMs
There are a couple issues to address. We have to choose a good...
- Baseline
- Regularizer
- Reward function
Baseline
Recall value function baselines and GAE. LLMs typically use a GAE baseline for the objective function. For PPO, we use a loss function for our value function estimator defined
Now, we do need to use our language model to produce estimates of our value function. We can either copy the LLM and train the copy to estimate the value function or add a second head to each output token that estimates the value of that token.
Also, the value function is typically not trained on the prompt, only on the response (the suffix of the prompt, typically, e.g. the last word of "What is the capital of France? Paris").
There's another way to compute baselines with LLMs that does not require an extra copy or head, which is in fact not applicable to general RL. We can estimate our baseline by using decision-time planning: we can "checkpoint" the current state of the LLM, and average across several trajectory samples branching out from the current state. This is possible because we can easily simulate multiple completions from the same LLM state, something that may not be possible for an autonomous driving RL problem. This is known as group relative policy optimization (GRPO), and is much simpler to implement :)
Regularization
Typically, this is done by simply adding a KL divergence term to the reward function with respect to some reference model, commonly the model produced by SFT.
Reward Function: Bradley-Terry Model (Preference)
Colloquially known as the "optometrist algorithm," since an optometrist asks a patient to compare two sets of lenses until they narrow it down to a good lens.
The algorithm proceeds as follows.
- Sample 2 or more trajectories .
- Ask a person to choose preference(s) in (i.e. pairwise ranking).
- Train reward using preferences.
- Train policy using .
But, how do we train ? We should use a probabilistic model to account for the stochasticity and noise of human decisions. In particular, we apply
which is actually just
This is precisely how ELO scores are calculated in chess!
So, to train , we simply do maximum likelihood estimation
Full RLHF Algorithm
- Sample 2 or more trajectories .
- Ask for human preferences .
- Train reward model .
- Train policy with reward .
Other Reward Sources
- Verifier reward: other model evaluates validity of answer
- Process reward: other model evaluates validity of chain-of-thought generation
RL with Partial Observability
The key difference between full observability MDPs and POMDPs is that POMDPs do not obey the Markov property! In particular, knowledge of makes knowledge of useless, but knowledge of does not make knowledge of useless. Therefore, knowing the history of observations can be useful.
POMDPs have some special properties when compared to normal MDPs.
- An optimal policy may engage in information-gathering actions.
- Some POMDPs do not have a deterministic optimal policy, only a stochastic optimal policy.
So, which methods can be applied to POMDPs?
- Policy gradients? Okay, provided advantage estimation does not rely on a value function (requires Markov property).
- Value-based methods? (e.g. -learning). Not okay, they always produce a deterministic policy and depend on producing the value as a function of the state (and you can't just replace the state with observations, sadly).
- Model-based methods? More on this later...
One critical idea in RL with partial observability is to use history states, where . History states, luckily, do obey the Markov property! This allows us to just use history states with our existing full observability RL methods. We'll discuss this in more detail next lecture :>