Lecture 16: Model-Based RL Algorithms
Planning with Models
Planning in RL describes, very generally, the process of using a model of our environment to make decisions without a policy.
Let's consider a deterministic dynamics, open-loop world model. Given an initial state , we use our model to compute the reward-maximizing sequence of actions, i.e.
where is given by our model at each time step, i.e. . Doing this directly works just fine, and produces an optimal solution.
But, what about a stochastic dynamics, open-loop world model? Well, we can do essentially the same thing, but compute the maximum in expectation, i.e.
where we must consider the distribution of possible states
In practice, however, with a model possessing stochastic dynamics, there are some complications. For one, the expectation must be approximated due to the typically large size of state and action spaces (e.g. via sampling). And, critically, this method is actually suboptimal!
Why is it suboptimal? It's primarily because the model is open-loop: it takes in the initial state, and then outputs a full sequence of actions to maximize expected reward. However, this produces suboptimal actions because, for instance, after transitioning to state , the optimal action may not follow the previously inferred sequence! This is because the uncertainty regarding the state transition has been resolved, allowing for a more optimal decision to be made at this point than what was previously inferred without this additional information.
Key Idea: new information helps us make better decisions!
Thus, for RL, we always used a stochastic dynamics, closed-loop model (unless the environment is truly deterministic, which doesn't really happen in the real world), in which our actor receives feedback from the environment about the actions its taken. Notably, the actor now takes some "policy" that reacts to the feedback its given—this diverges from our notion of planning, and in fact is really just standard reinforcement learning.
So, how can planning methods be useful? Actually, we can employ open-loop planning methods within a closed-loop RL method to great effect.
For instance, a simple idea is to, at each step of the closed-loop RL method, use an open-loop planning method to decide a short sequence of actions that does not induce execution until the end of the entire horizon, but merely from time step to , for some small . This is effectively the same as action chunking, which we discussed briefly in Lecture 3.
But first, let's describe some simple open-loop planning methods, before we discussing embedding them into a closed-loop method.
Stochastic Optimization / Random Shooting
Stochastic optimization is the simplest open-loop planning method.
First, let's briefly clarify some notation. The objective of optimal control/planning is to compute
for some objective function (e.g. expectation of the sum of rewards). We will define so we may write this concisely as
Stochastic optimization is really just "guess and check," i.e. it
- Picks from some distribution (e.g. uniform).
- Choose based on .
This is computationally cheap (provided parallelization is possible, which is likely). However, the performance of this method depends heavily on dimensionality (high dimensionality is very bad) and the landscape of the objective function (low entropy distribution is bad).
Cross-Entropy Method (CEM)
The CEM method is a small modification to stochastic optimization that produces significant performance improvements. In essence, rather than simply sampling all from some distribution, we sample a set multiple times. Between iterations, we change our sampling distribution to place more probability mass on the existing "good" samples seen in past iterations. This idea is illustrated below, where the yellow samples are the first iteration, the green samples are the second iteration of samples, and the blue curves represent the changing sample distributions (uniform wide curve narrow curve).
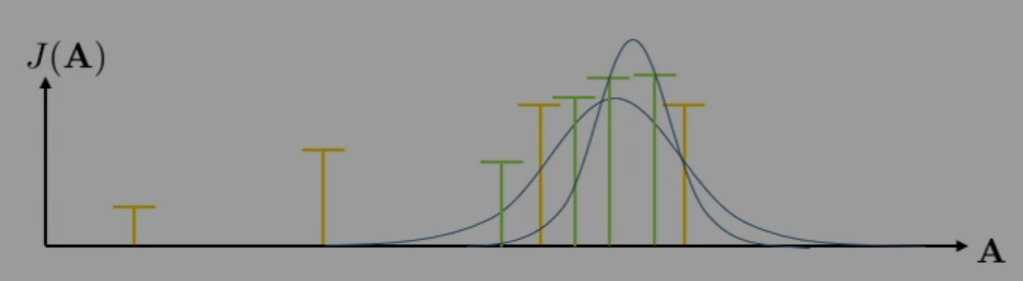
Here's the algorithm steps.
- Sample .
- Evaluate .
- Pick high-value elites where .
- Refit to elites .
This performs much better than stochastic optimization, while being almost just as simple and still very efficient. Unfortunately, it does still suffer from the curse of dimensionality.
Other Methods
- Monte Carlo tree search (MCTS)
- Continuous trajectory optimization (LQR, etc.)
- Tree-based motion planning (RRT)
How to Plan with Uncertainty
With a deterministic setting, we simply have
In the stochastic setting,
where we are averaging over samples.
Given the uncertainty of the model, we may use a bootstrap ensemble (see Lecture 15) for to reduce distributional shift, which is typically some distribution over deterministic models. Notably, there are two choices for our bootstrap ensemble of when we "sample" a model from the distribution:
- Sample a single model for each , and use it over the whole trajectory
- Sample a new model for every (each time step in each trajectory).
However, it typically is more sensible to keep a model constant across a trajectory . Otherwise, we're effectively changing our simulated environment every single step—this is bad, because while each environment model in the ensemble is somewhat probable, though perhaps uncertain, a combination of the models, each used at different time steps, may be a very unlikely representation of the environment!
In general, for a candidate action sequence ,
- Sample (sample environment model parameters from bootstrap ensemble).
- At each time step , sample (sample from environment model).
- Calculate .
- Repeat and accumulate average reward.
This, consequently, computes the value of for some candidate while considering both our epistemic uncertainty about the model's accuracy and the aleatoric uncertainty of the model with regards to the state transitions.
Policy Learning with Models
Let's now return to the stochastic, closed-loop case, or standard RL augmented with an environment model.
Model-free Optimization with a Model
First, we'll discuss how we may simply augment our existing, model-free methods with the use of a model. The simplest approach is to just use policy gradient, but use our model to generate samples.
- Gather samples from environment model
- Optimize policy gradient for a few steps
- Run policy in the real world to generate data to improve our environment model
Notably, though, policy gradient was previously inspired by a lack of knowledge of environment dynamics, and thus relied on samples to estimate —this is known as a likelihood gradient. But, one might notice that, with our environment model's estimate of the dynamics, we can actually perform backpropagation through (the trajectory in) our model to estimate —this is known as a pathwise gradient. Is this better?
The pathwise gradient does reduce variance compared to the likelihood gradient since it is no longer Monte Carlo; however, the pathwise gradient also suffers from severe ill-conditioning due to the multiplication of many (about , the horizon length) Jacobians! Thus, in practice, the standard policy gradient is often more stable than the pathwise gradient, provided sufficient samples.
Key Idea: Backpropagation through learned dynamics generally doesn't perform well due to ill-conditioning.
So, here's our new policy gradient model-based RL algorithm.
- Run base policy to collect .
- Learn dynamics model to minimize .
- Use to generate trajectories with policy .
- Use to improve via policy gradient.
- .
Note that steps 3-4 are often repeated several times before collecting more data from the real world, to improve sample efficiency.
This method still has some problems, though. In particular, it suffers from the curse of model-based rollouts. In essence, the error caused by distributional shift accumulates quadratically in the length of the horizon. Thus, if we sample long trajectories produced by policy from our dynamics model , the trajectories may become extremely inaccurate!
Thus, we'd like to use our model only for short rollouts. How? We could try simply shortening the task horizon, but for tasks where certain states may only appear in later time steps, this may result in the model never fully learning what it needs. (E.g. model performing a task that is physically impossible to complete within the horizon).
Instead, a more effective method is to generate long rollouts from the real world environment, and then generate short rollouts from by starting, not from the initial state, but from randomly selected states observed from the real world trajectories (our replay buffer). This reduces our distributional shift error while also allowing the model to see all time steps. However, our state distribution isn't right anymore—our state distribution is now sampled from the states in the replay buffer, which are sampled from older policies. Luckily, our state distribution generally does not diverge too much, and thus this is an acceptable compromise (primarily for off-policy methods, which are more tolerant of this divergence).
So now, here's the modified algorithm.
- Run base policy to collect .
- Learn dynamics model to minimize .
- Pick states from , use to generate short rollouts with policy .
- Use both real and model data to improve via off-policy RL.
- .
This algorithm is very similar to Dyna, which was an early algorithm that performed model-free RL with a model. It's essentially online -learning augmented with a model.
-
Given state , pick action using exploratory policy
-
Observe to produce transition .
-
Update model and using .
-
Perform -update (usual Q-learning update)
-
Repeat times:
- Sample , buffer of past states and actions
- Perform -update
This inspired the general "Dyna-style" class of methods.
-
Collect transition data of .
-
Learn model , possibly too.
-
Repeat times:
- Sample , the buffer
- Choose action (from , or at random)
- Simulate , too if relevant.
- Train on with model-free RL.
- (Optional) take more model-based steps to produce short rollout
Note how our algorithm falls into this Dyna-style class.
We can generalize these algorithms further as model-accelerated off-policy RL. We can interpret our methods as a composition of several independent processes, similar to -learning (see [[Lecture 8#More Efficient -Learning|Lecture 8]]). Note also that we may tune the relative speeds of these processes to produce algorithms with different levels of sample efficiency, learning speed, etc.
- Data collection from real world
- Target update
- -function regression
- Dynamics model training
- Data collection from model
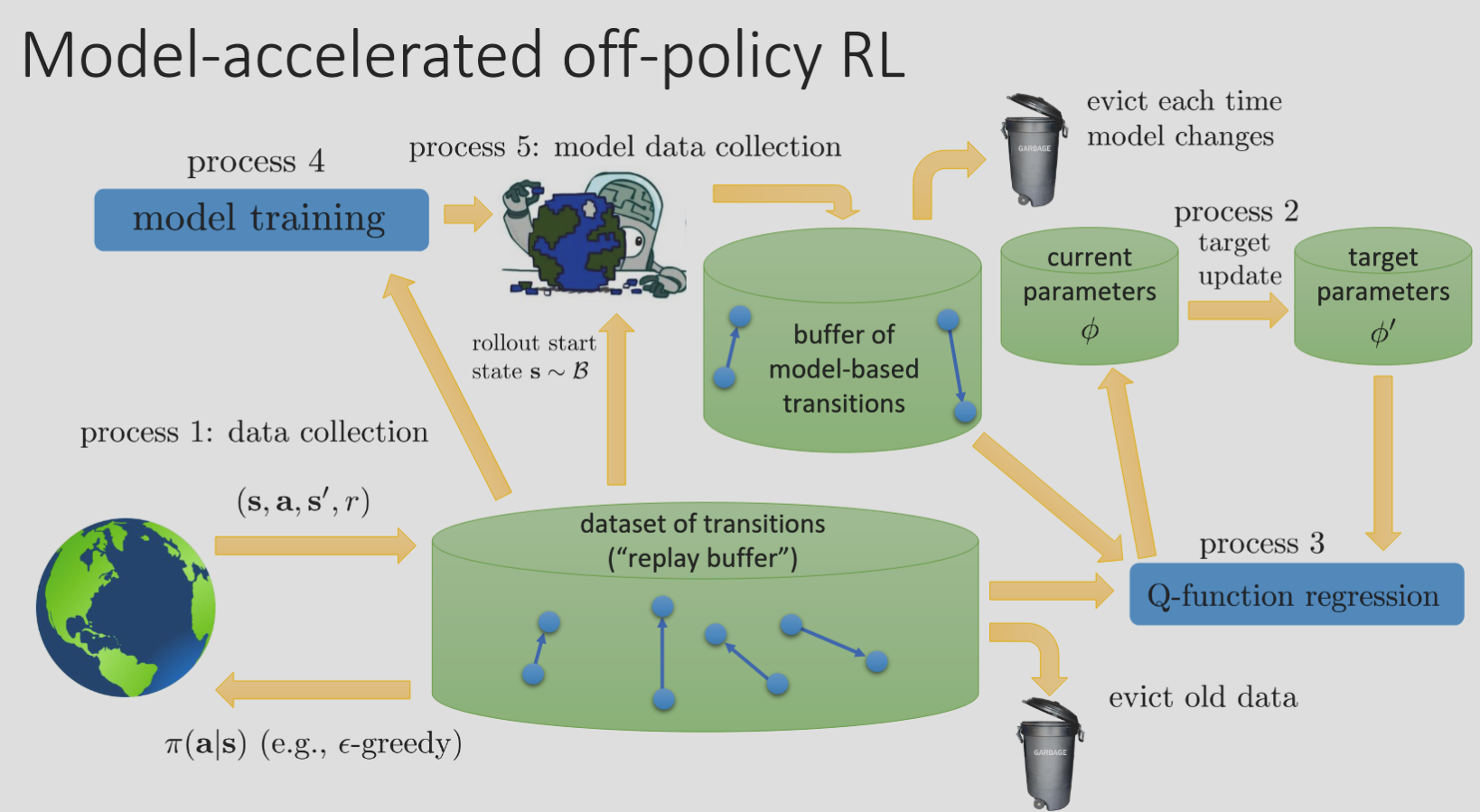
Some actual algorithms that follow this framework:
- Model-Based Acceleration (MBA, Gu et al.)
- Model-Based Value Expansion (MVE, Feinberg et al.)
- Model-Based Policy Optimization (MBPO, Janner et al.)
Representing the Model
Now, let's discuss the architecture of the dynamics model itself.
Latent State Space Models
Let's consider a partially observed MDP. There is, naturally, some latent state space underlying this MDP. Oftentimes, we'd like to learn this underlying state space, primarily because it may be low-dimensional (relative to the observation space) or it may otherwise simply be easier to run RL on. In particular, we'll be using VAEs (see Lecture 12), which, if you'll recall, attempt to model a latent space underlying a distribution .
In our case, and . In order to use a VAE, we need to determine our prior . Well, we know that the true distribution is defined as
We can choose to be any (typically simple) distribution, e.g. . However, the probabilities are the transition probabilities, and thus must be learned—this is the job of our dynamics model.
We also need to determine our decoder . Well, based on the structure of the POMDP,
as the observation at time step is independent of all other states besides the state at time step (due to the Markovian nature of the states). The separation of the different time steps usually means our decoder is some neural network.
Finally, we need to determine our encoder . There are actually many different choices, but one choice is to factor the encoder over time steps (known as a filtering posterior):
Since the encoder takes in all previous observations and actions, and outputs a distribution over states, it's usually some sequence model, e.g. a transformer.
Let's now put these together. We have the following models, which represent our POMDP.
- : observation model (decoder)
- : dynamics model
- : reward model
And we train our latent space model with
which is just produced by substituting into our previous VAE equations. Note that the expectation is performed w.r.t. .
Choice of Encoder
There's some interesting analysis to be done, though, with regards to our choice of encoder. Recall that we previously chose a filtering posterior
which is a good, simple posterior, but has a major limitation: it treats the distributions of and as independent, and since the expectation is taken w.r.t. , we are essentially computing the expectation with respect to all pairs of states sampled from our model! In reality, though, each is only likely to transition to a much smaller subset of possible 's.
This gives rise to a common problem in variational inference known as posterior collapse, in which insufficient dependencies between the latent variables induces erroneously . The idea is that the filtering posterior has difficulty learning because it's attempting to learn a transition between two independent states; therefore, the encoder simply decides to minimize the divergence penalty rather than the "reconstruction" penalty, since it cannot effectively minimize the reconstruction penalty.
While this can be problematic, in instances where the observations already capture much of the state, and what's really desired is the use of VAE to disentangle the underlying factors of variation of the state and learn a nicer representation of the state, this works fine!
However, if this is a limitation for the problem, there are other posteriors we can use. In particular, the full smoothing posterior
which takes as input the actions and observations over the entire horizon. This is, of course, a more complex model. However, now the dynamics model will receive samples that are highly correlated, and can more easily learn.
Alternatively, we can go to the opposite extreme, if we desire an even simpler model, and use a single-step encoder:
This is okay if we are in an almost fully observed MDP, i.e. each observation almost entirely capture its corresponding state.
Generally speaking, the filtering posterior is the most balanced choice, but the choice of encoder can change depending on the problem. (The single-step encoder and filtering posterior are pretty common).
Simple Latent Space Model Analysis
What if we wanted to make the simplest latent space model? We'll use a single-step encoder, and we will even define to be deterministic. In other words,
for some function . (Note that is the Dirac delta function, and represents the concentration of all probability mass at a single point).
Now, let's analyze our training equation. First, we can remove our expectation and substitute in everywhere was used, since is now deterministic. Additionally, we may delete the entropy term from the expression since it is effectively useless now; is a Dirac delta function and thus its entropy (which is technically , FYI) cannot change.
Intuitively, this is saying that, w.r.t and , we maximize the probability of decoding back to (second term) and the probability that obeys the learned dynamics (first term), over all trajectories and time steps. This should make sense!
Of course, without any uncertainty or handling of partial observability, this only really works when you just desire a compact representation/encoding of your state.
This is known as an autoencoder, without the "variational" because all stochasticity has been removed from the model.
This is just an autoencoder. To make it into an actual model-based RL objective, we just add a reward model term to the end of our objective.
Actor-Critic with Learned Representations
We can add these latent state space models to our existing model-free methods, like actor-critic, to produce an actual algorithm.
- Get by taking one step with , store in replay buffer .
- Update the model: , , , using a batch .
(dynamics, reward, decoder, and encoder models, respectively) - Infer and . (Note that may be encoded jointly if using a full smoothing posterior).
- Evaluate target value .
- Approximate with e.g. reparameterized policy gradient.
- .
Actor-Critic with Model-Based RL
Returning to the ideas in [[#Policy Learning with Models]], we can produce an actor-critic algorithm that uses the dynamics model to simulate more data.
-
Get by taking one step with , store in replay buffer .
-
Update the model: , , , using a batch .
(dynamics, reward, decoder, and encoder models, respectively) -
Infer and . (Note that may be encoded jointly if using a full smoothing posterior).
- Simulate additional data with .
- Evaluate target value .
- Update with .
- Approximate with e.g. reparameterized policy gradient.
- .