Lecture 17: Offline Reinforcement Learning
Introduction
Recall on-policy and off-policy RL. In both classes of algorithms, data is collected by running a policy in the real-world/simulator (off-policy RL collects more data to add to the replay buffer). Offline RL is somewhat similar to off-policy RL, except the replay buffer is static; no additional data is collected during training.
First off, how is this even possible? RL is seemingly centered around this "trial and error" approach that allows a model to test policies in the real-world and subsequently optimize. Intuitively, it's because
- Offline RL finds the "good behaviors" in a static dataset
- Good behavior in one region may suggest good behavior in another region
- Components of good behavior can be "stitched" together to produce more complex, good behavior
Notably, offline RL also differs from imitation learning in that the dataset may not consist of optimal trajectories! Offline RL makes no assumption about the quality of the dataset.
Distributional Shift
First, we will assume our dataset is generated by some policy , and that we are maximizing the usual, discounted RL objective w.r.t. policy
Unfortunately, running any of our usual model-based or model-free RL algorithms will run into serious distributional shift problems between our behavior policy and our target policy. This is actually a "surface symptom" of a deeper, more fundamental problem: counterfactual queries. Counterfactual questions ask about "what if" scenarios; in RL, this means determining how good some action is when it's never been seen before in training data. With online RL, this is resolved by simply trying out the action; in offline RL, this is not possible. So, how do effectively generalize in offline RL to unseen data?
Intuitively, distributional shift occurs because RL methods inherently maximize when producing some policy evaluation or policy prediction function; this encourages maximization even over the errors of the model, like what we saw in [[Lecture 8#Overestimation in -Learning|Lecture 8]] with -learning. (If minimizing a function, e.g. loss, still maximizing error; just in the other direction). Moreover, techniques like importance sampling in off-policy RL methods that correct for the divergence between distributions typically incur high variance (for importance sampling, this is due to the multiplication of many importance ratios).
However, off-policy RL methods like PPO typically include some term in the objective function that constrains distribution divergence, i.e. a KL divergence term. This is known as a policy constraint, and, as we'll soon see, some type of policy constraint exists in practically all offline RL methods.
In short, the existing challenges with sampling error and function approximation in standard RL become more severe in offline RL.
Policy Constraints
First, there a few principles for offline RL that, empirically, have proved effective.
- Use value-based/model-based methods.
- Somehow fix distributional shift
- Policy constraints
- Pessimism
- Avoid out-of-distribution actions in updates
A simple policy-constrained offline RL algorithm can be derived just from a standard off-policy policy gradient.
Actually, we can also use the reverse KL divergence, which swaps and , instead of the forward KL divergence. Is there a difference? Well, the two are, mathematically,
Consider the first equation, i.e. forward KL divergence. First, note that the entropy term is essentially just an additive constant, since changing does not change the entropy of the distribution . For any sample that has a probability of under and a nonzero probability under , the overall expression diverges to ; in other words, an extremely harsh penalty for assigning a probability of to any sample in . Meanwhile, it doesn't significantly encourage the assignment of higher probabilities to any samples; thus, this induces the assignment of moderate probabilities to most actions. This leads to a phenomenon known as mode covering, in which generates a broader distribution to cover all the data.
In contrast, reverse KL divergence encourages to choose actions that are high probability in , and doesn't strongly penalize for perhaps missing out on other actions. And, for any sample that has a probability of under , the overall expression diverges to ; in other words, an extremely harsh penalty for assigning a nonzero probability to any sample with probability under . This encourages mode seeking, in which generates a narrower distribution to cover a specific, high-probability mode of the distribution.. An illustration of mode seeking vs. mode covering is shown below.
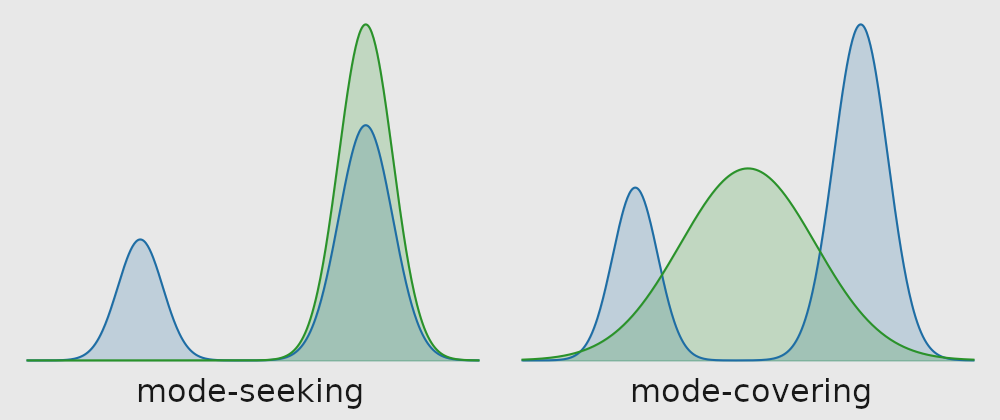
Why choose one over the other?
- Forward KL
- Avoids reward hacking
- Good if we don't know (reuse samples)
- Good if we don't want to lose some modes (e.g. LLM)
- Reverse KL
- Avoids unobserved actions
- Good if you want the "best mode inside data"
- Good with max-entropy RL
- Requires estimating
Typically, though, forward KL is chosen because it's simply much easier to implement!
As a sidenote, one may use non-KL-based policy constraints, e.g.
which essentially allows assigning probability in to only states seen in , and has no additional term to encourage entropy in the distribution. Due to practical challenges (difficult to approximate tractably), though, such a constraint has seen limited use.