Chapter 3: Probability and Information Theory
3.2 Random Variables
A random variable is a variable that can take on different values, each associated with some probability. It may be discrete (finite/countably infinite number of states) or continuous (any real value).
3.3 Probability Distributions
A probability distribution describes the probabilities associated with the values of a random variable. For discrete variables, it is described by a probability mass function (PMF). For continuous variables, the analogue is a probability density function (PDF).
A PMF must satisfy the following properties
- The domain of must be the set of all possible states of
- , .
- .
A PDF must satisfy the following, similar properties
- The domain of must be the set of all possible states of
- . Notably, it is not required that .
- .
is not required for a PDF because there are an uncountably infinite number of different states of , and therefore would not cause .
Also, the nomenclature of a PDF (density instead of mass) is motivated by the fact that it does not actually provide the probability of a specific state directly; instead, the probability of landing inside an infinitesimal region with volume is provided by . (After all, the chance of each specific state is effectively , considering the uncountably infinite set of states).
Finally, we note the existence of joint probability distributions, distributions over many variables simultaneously, represented by .
3.4 Marginal Probability
Consider a joint probability distribution. A marginal probability distribution is a probability distribution over a subset of its parameters/variables.
For instance, consider the joint probability distribution . Then,
For continuous variables, summation is simply replaced by integration.
3.5 Conditional Probability
Conditional probability is the probability of an event occurring given the occurrence of another event has already happened. This is denoted by , and is calculated as
and is only defined when .
3.6 The Chain Rule of Conditional Probabilities
A joint probability distribution over several random variables can be decomposed into the product of several conditional distributions, each over only one variable.
For instance,
The proof of this follows inductively from the definition of conditional probability.
3.7 Independence and Conditional Independence
Two random variables and are independent if their probability distribution can be expressed as
Two random variables and are conditionally independent given a random variable if the conditional probability distribution over and factorizes in this way (i.e. the above equation) for all values of .
Independence and conditional dependence are denoted and .
3.8 Expectation, Variance, and Covariance
The expectation or expected value of a function with respect to probability distribution is the mean value of when is randomly sampled from .
Expectation is linear, i.e. the Linearity of Expectation tells us that
Variance is a measure of how much a function of a random variable varies across samplings, and is described by
Standard deviation is .
Covariance describes how closely two values are linearly related.
The covariance of a value with itself is simply the value's variance.
Notably,
Correlation is essentially correlation except each variable is normalized.
Note that independent variables have zero covariance, and variables with nonzero covariance are dependent. However—dependence and covariance are not the same. Two variables may be dependent and have zero covariance.
The covariance matrix of a random vector is an matrix such that . We note that the diagonal elements of the covariance simply give the variances .
3.9 Common Probability Distributions
Bernoulli
A distribution over a single binary random variable, parameterized by a single such that . It possesses the following properties.
Multinoulli
Also known as the categorical distribution, it describes a single random variable with (finite) different states—effectively the generalization of a Bernoulli variable. It is parameterized by a vector where denotes the probability of the th state and the final, th state's probability is given by . Note that is a necessary constraints.
Gaussian Distribution
Also known as the normal distribution, it is parameterized by , the mean, and , the standard deviation. Its probability density function (PDF) is described by
Frequently, the distribution is parameterized by instead of where the two are related by to make evaluation of the PDF more efficient. is known as the precision or inverse variance. This does not change the distribution's behavior.
The normal distribution is frequently used as a default choice for two reasons.
- The central limit theorem states that the sum of many independent random variables is approximately normal.
- The normal distribution encodes the maximum amount of uncertainty over .
The normal distribution may also generalize to as the multivariate normal distribution, where is replaced with a positive definite symmetric matrix that provides the covariance matrix of the distribution.
Where and are now vectors instead of scalars. As before, it is possible to replace with a precision matrix for increased efficiency of evaluation.
Frequently, the covariance matrix is fixed to be a diagonal matrix. Sometimes, the covariance matrix is also a scalar multiple of the identity matrix, in which case the distribution is known as an isotropic Gaussian distribution.
Exponential and Laplace Distributions
In deep learning, it's often desirable to have a probability distribution with a sharp point at . The exponential distribution provides this! It is parameterized by , and is described by
Where is an indicator function that assigns probability for all .
A related distribution is the Laplace distribution, which places a sharp peak of probability mass at an arbitrary point . It is parameterized by and a variable .
The Dirac Distribution and Empirical Distribution
Occasionally, it is desirable to place all probability mass in a distribution at a single point. This can be done by defining a PDF with the Dirac delta function , which is parameterized by the desired point .
This is essentially defined such that it is zero-valued everywhere except , but integrates to .
The Dirac delta function is not an ordinary function that associates each input with an output. Instead, it is known as a generalized function, which is defined in terms of its properties when integrated.
The Dirac delta distribution is also commonly used to construct an empirical distribution for continuous variable.
Which essentially evenly distributes probability mass across the points (of some dataset of size ) (each with mass). This essentially discretizes the distribution. (For discrete variables, the empirical distribution is trivially represented with a multinoulli distribution).
In the context of deep learning, the empirical distribution may represent the proportion of the dataset each item of training data may represent (given possible imbalances in frequencies of training data).
Mixtures of Distributions
It's also possible to define probability distributions by combining several others together. Sampling from such a mixture distribution involves first randomly choosing a component distribution, according to some multinoulli distribution, and then sampling from this component distribution. Thus, the probability of choosing some from this mixture distribution is
Where is the multinoulli distribution over the different component distributions. is known as the component identity random variable.
The empirical distribution is a mixture distribution composed of several Dirac components.
The mixture model hides a much more interesting concept, which will be discussed in depth later in section 16.5. A latent variable is a random variable that cannot be observed directly. In this case, the component identity random variable is a latent variable, and is related to the random variable through a joint distribution, i.e. .
A common type of mixture model is the Gaussian mixture model, in which the components are distinct Gaussian distributions. The parameters of a Gaussian mixture model, beyond its usual means 's and covariances 's, also includes a prior probability for each component . This is just the parameter for the multinoulli distribution across the component distributions. Its nomenclature notes that represents the model's beliefs about before it has observed , the result of sampling the Gaussian mixture. Meanwhile, is a posterior probability, as it represents the model's beliefs about after it has observed .
What does this even mean, though? Well, in real-world instances, where we don't know the distribution that describes a dataset, it's desirable to iteratively compute a closer and closer approximation of the distribution. This is known as Bayesian inference, and Gaussian mixture models are frequently used for this process because they are universal approximators of densities, i.e. any smooth density function/distribution can be approximated with arbitrarily small, nonzero error by a Gaussian mixture model with enough components.
Thus, during Bayesian inference, the prior probabilities represent the model's beliefs about the distribution of the component Gaussians, and the posterior probabilities represent the model's updated beliefs about the distribution after observing a new data point sampled from the real-world distribution.
Think of Gaussian mixture models as the equivalent of a Taylor series for density distributions.
3.10 Useful Properties of Common Functions
Some functions commonly appear when working with probability distributions.
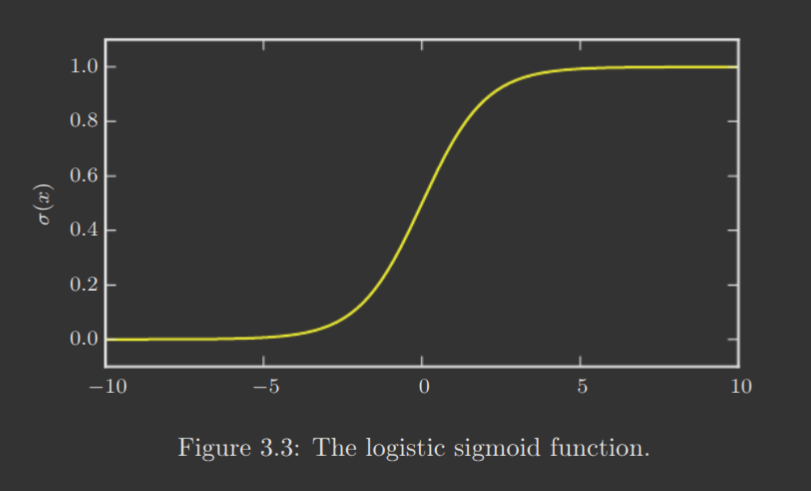
The logistic sigmoid is described by
and is frequently used to produce the parameter of a Bernoulli distribution because its range is . Notably, the sigmoid function saturates when its argument is very positive or very negative, i.e. becomes small.
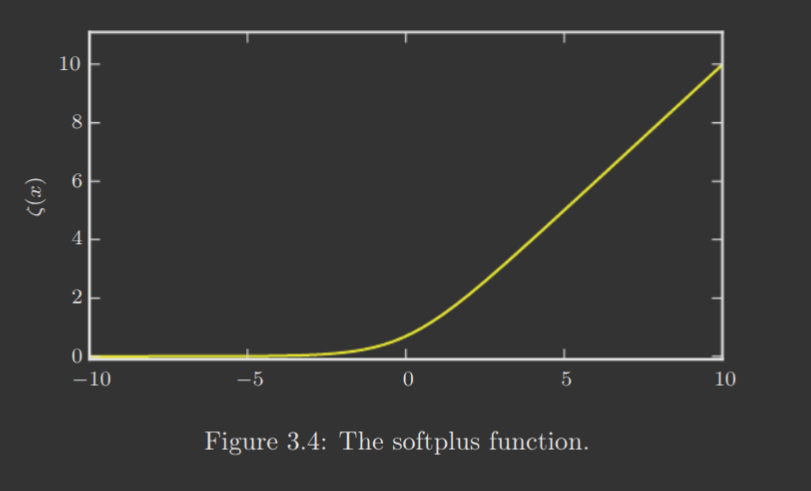
The softplus function is described by
and is frequently used to produce the or parameter of a normal distribution because its range is . It's also frequently observed when working with sigmoids. Notably, its name describes its initial design—a smoothed or "softened" version of .
Now, a list of some mathematical formulas involving these functions.
is called a logit.
Also, note that the last equation, , resembles , where and . This is partly why was chosen for "softplus" purpose.
3.11 Bayes' Rule
In essence,
3.12 Technical Details of Continuous Variables
It's necessary to briefly discuss some details of measure theory to formalize some of our notions of continuous variables. For our purposes, we mostly care about measure theory when describing theories that applies to most, but not all, points in .
A set of points that is negligibly small is said to have measure zero. Intuitively, this means such a set occupies no volume in the space we are measuring. For instance, in , a 3D object has positive measure, but a 2D (polygon) or 1D (line) has measure zero. Also, note that the union of countably many sets that each have measure zero also has measure zero. In particular, the set of all rational numbers has measure zero in because , and has measure zero.
Almost everywhere is also a useful term for us from measure theory. It is a qualifier for a property that holds throughout all of space except on a set of measure zero. As the exceptions occupy a negligible amount of space, they are ignored for most applications. There are some results in probability theory that hold for all discrete values but hold only "almost everywhere" for continuous values.
Finally, another technical detail of continuous variables involves continuous random variables that are functions of one another. Consider random variables and , such that and is an invertible, continuous, differentiable transformation. Perhaps contrary to expectations, .
Consider, for instance, and , i.e. the uniform distribution over . If we used the false equation above, i.e. , this would imply , which leads to the conclusion when , and otherwise. Then, this would imply
which is obviously invalid for a density distribution.
Why is this approach wrong, then? It's because it fails to consider the distortion of space caused by . The probability of lying in an infinitesimally small region with volume is given by . However, the infinitesimal volume surrounding in space may have different volume in space, since can transform the scale of space.
We can correct the issue, though. We just need to preserve
We can derive from this
In higher dimensions, generalizes to the determinant of the Jacobian matrix, i.e. the matrix with .
3.13 Information Theory
Information theory is the study of quantifying how much information is present in a signal. However, it's useful for us to characterize probability distributions or quantify similarity between distributions.
The fundamental idea in information theory is that learning that an unlikely event has occurred is more informative than learning that a likely event has occurred. More specifically,
- Likely events have low information content. Guaranteed events have zero information content.
- Less likely events should have higher information content.
- Independent events should have additive information, e.g. learning a coin came heads up twice conveys twice as much information that learning a coin came heads up once.
A metric that satisfies all three of the above properties is the measure of the self-information of an event .
In this book, always means the natural logarithm.
With , is in the units of nats. One nat is the amount of information gained by observing an event of probability . Had we used , this would be replaced by bits or shannons. The idea is the same, however.
This function can naturally be applied to discrete variables. However, continuous variables lose some properties—an event with unit density (i.e. a single point in the continuous domain) has zero information, despite not being guaranteed to occur.
Self-information also considers only a single outcome. The uncertainty in an entire probability distribution can be quantified with Shannon entropy.
This is also denoted , and describes the expected amount of information provided by an event drawn from the distribution . It simultaneously provides a lower bound on the number of bits needed, on average, to encode symbols drawn from a distribution . Nearly deterministic distributions have low entropy; near uniform distributions have high entropy. When is continuous, Shannon entropy is additionally known as differential entropy.
We can also measure the difference between two distributions and over the same random variable using Kullback-Leibler (KL) divergence.
For discrete variables, it can be interpreted (in information theory terms) as the extra amount of bits/nats required to send a message containing symbols drawn from a probability distribution when using a code designed to minimize the length of messages drawn from probability distribution .
KL divergence has several useful properties.
- .
- exactly for discrete variables or "almost everywhere" for continuous variables
is not a true distance measure between distributions because it is asymmetric. for all .
A closely related quantity to KL divergence is the cross-entropy .
Minimizing cross-entropy with respect to is equivalent to minimizing the KL divergence, since is entirely dependent on (recall that is the Shannon entropy of a distribution ).
frequently appears with these expressions. By convention, these are treated as .
3.14 Structured Probabilistic Models
Frequently, in machine learning, we frequently encounter probability distributions over a very large number of random variables, but with relatively few interactions between variables. Using a single function to describe the joint probability distribution is, thus, very inefficient. Instead, it's better to factor the distribution into many factors.
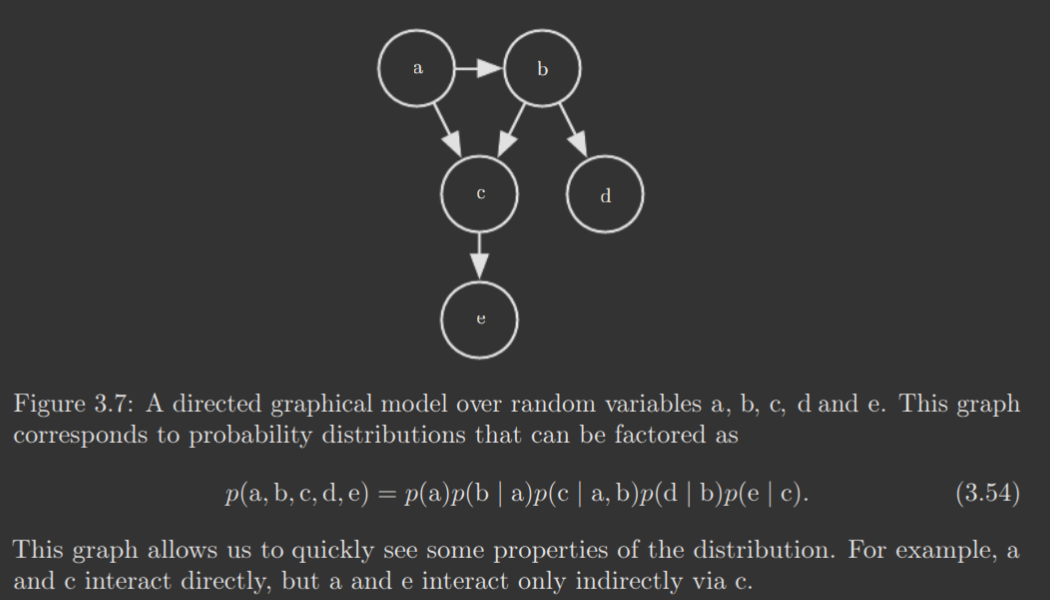
Consider three random variables , such that influences and influences , but are independent given . Then, we can factor the probability distribution as
These factorizations significantly reduce the number of parameters required to describe the distribution, as each distribution 's number of parameters is exponential in the number of variables in . (e.g., has parameters while has ).
A probability distribution's factorization is frequently described using a graph, known as a structured probabilistic model or graphical model.
There are two types of structured probabilistic models: directed and undirected. In both graphs, each node corresponds to a random variable, and each edge denotes a direct interaction between and .
Directed models represent factorizations into conditional probability distributions, like above. In particular, a directed model contains one factor for every random variable in the distribution, and that factor consists of the conditional distribution over given the parents of , denoted .
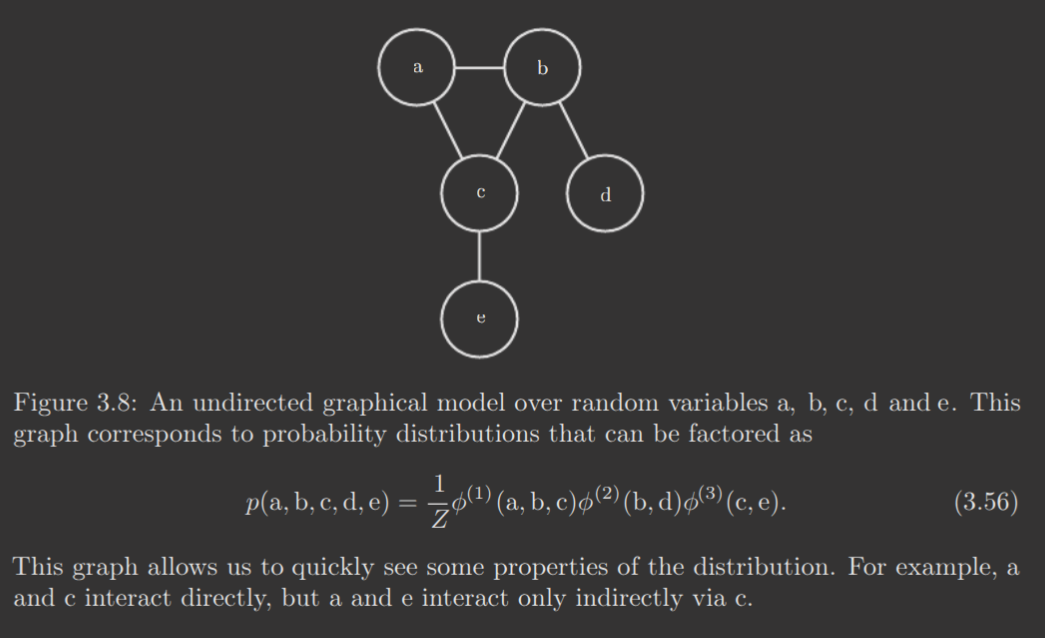
Undirected models represent factorizations into a set of functions that are typically not probability distributions. Any subset of nodes that is fully connected in is called a clique. Each clique in an undirected model is associated with a factor , which, again, is not a probability distribution but any function such that its range is nonnegative.
The probability of a certain assignment/results of the random variables is proportional to the product of all of these factors, when provided the input of the assignment. In order to convert this to probabilities, a normalizing constant is applied, where is the sum or integral of all states of the functions and
Notably, these two graphical representations of factorizations do not denote two mutually exclusive families of probability distributions; a probability distribution may be described with either method.