Chapter 4: Numerical Computation
4.1 Overflow and Underflow
Continuous mathematics (i.e. ) is not perfectly precise on computers, due to the finite limitations of the real-world. Thus, there can be errors. Underflow is a rounding error that occurs when numbers near zero round to zero, which can significantly impact some functions. Overflow is a rounding error that occurs when numbers with large magnitude are approximated as or , which often becomes NaN, or Not-a-Number, in software.
Softmax is one such function that is vulnerable to underflow and overflow. It is frequently used to predict probabilities associated with a multinoulli distribution, and is described by
Consider an instance in which all . If is very negative, will underflow, resulting in a denominator of . If is very large and positive, will overflow, resulting in an undefined .
This is commonly resolved by instead evaluating , where . This ensures the largest argument passed to softmax is , preventing overflow, and at least one term in the denominator has a value of (since the corresponding to is ).
However, underflow in the numerator can result in the function evaluating to . This is problematic if we attempt to evaluate , which would (erroneously) return . This can be stabilized in a similar method as above.
4.2 Poor Conditioning
Conditioning describes how rapidly a function changes with respect to changes in the input. A high condition number indicates high sensitivity to changes in input. This is problematic because rounding errors can cause large changes in the output of poorly conditioned functions.
Consider, for instance, the function . If has an eigenvalue decomposition, its condition number is
Hence, a poorly conditioned matrix would amplify existing errors when multiplying by the inverse.
4.3 Gradient-Based Optimization
Optimization, here, describes the task of minimizing/maximizing some objective function or criterion by iteratively changing . Typically, minimization is done (as maximization of is the same as minimizing ). For minimization, may also be called the cost/loss/error function. Also, we frequently denote .
Consider a function that we seek to minimize. The derivative provides the slope of at . Intuitively, this implies that how a small change in the input will impact the output, i.e. . This is useful, because, in order to reduce , we can simply move in small steps in the direction opposite the sign of the derivative. This simple concept is what underlies the famous technique gradient descent (in the 2D case) invented by Cauchy in the 1800s.
But what if ? As you may recall, such points are known as critical points or stationary points. These points can be local minimums, local maximums, or saddle points. A 2D representation of all three are provided below.
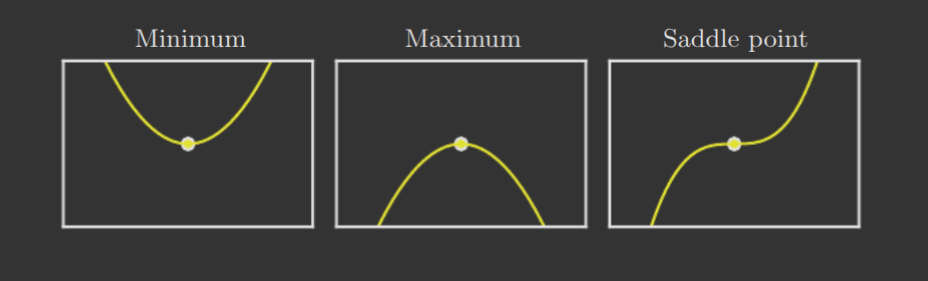
Of course, local minimum are not necessary the absolute minimum. The absolute minimum of is known as the global minimum. Optimization is not trivialized by gradient descent because, by nature, gradient descent finds local minimums. For complex, real-world problems filled with many suboptimal local minima, this may not be desirable.
We often consider functions in higher dimensions, too. Note, though, that the function must still have scalar output, i.e. . For functions with higher dimensional inputs, partial derivatives come into play, and the gradient replaces the derivative. The gradient is defined as
or the vector of all the partial derivatives of with respect to its inputs. Meanwhile, critical points are now points where
The directional derivative in direction (a unit vector) is the slope of the function in direction . In other words, it is
By chain rule, this is equivalent to
In order to perform gradient descent and minimize in higher dimensions, we must compute the direction in which decreases the fastest. This can be computed using the directional derivative.
This is equivalent to
by the dot product formula. Considering and that does not influence the value of the gradient, this simplifies to
Naturally, this is minimized when . In other words, points in the opposite direction of the gradient. Thus, moving in the direction of the negative gradient produces the steepest descent.
So, this technique suggests a new point
But what should we set to?
is known as the learning rate, and essentially determines the step size of the gradient descent. Typically, is set to a small value—large step sizes may significantly overshoot the local area in which this negative gradient direction is optimal. An alternative approach is to evaluate for several choices of , and choose the value that returns the smallest objective function value. This technique is known as line search.
Steepest or gradient descent converges when . In most real-world instances, this requires an iterative process; however, it may even be possible to directly compute the critical point by solving the above equation.
Gradient descent is specific to continuous spaces. The discrete analogue is known as hill climbing.
Jacobian and Hessian Matrices
Now, we introduce some more advanced mathematical tools for further exploration.
The Jacobian matrix of a function is a matrix such that , i.e. the partial derivative of the th element of the output of with respect to the th element of the input.
The Hessian matrix of a function (scalar output) is a matrix such that
The Hessian can also be interpreted as the Jacobian of the gradient.
Notably, if the second partial derivatives are continuous at some point , the differential operators are also commutative, i.e.
Thus, , so the Hessian is symmetric at all such points. Since the Hessian is real and symmetric, it has an eigendecomposition!
Consider that the second derivative in a specific direction, represented by unit vector , can be computed by . If is an eigenvector of , the second derivative is simply the corresponding eigenvalue. Otherwise, it is a weighted average of the eigenvalues with weights in , where eigenvectors whose angle with is smaller receive higher weights.
Recall from section 2.7 that:
The eigendecomposition of a real symmetric matrix can also optimize quadratic expressions of the form subject to the constraint . The maximum value of is the maximum eigenvalue, and the minimum is the minimum eigenvalue.
Thus, the maximum eigenvalue of determines the maximum second derivative, and similarly for the minimum.
It turns out that the directional second derivative can be used as an indicator of how well a gradient step will perform.
You may recall that the second derivative, in two dimensions, describes the curvature of a function, as seen below. What we soon discuss is precisely the same concept, except applied to higher dimensions.
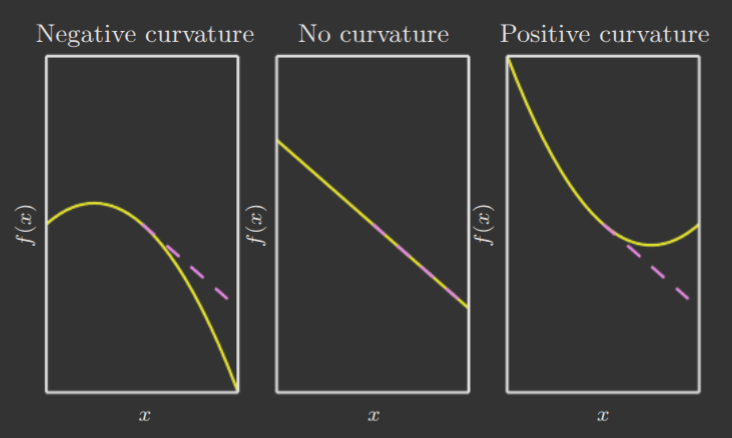
In the content of gradient descent, negative curvature implies the function decreases faster than the gradient predicts. Positive curvature implies it decreases slower, and that large steps can inadvertently increase the cost.
In higher dimensions, we can effectively replace first derivatives with the gradient and second derivatives with the Hessian. So, extending a second-order Taylor series approximation of around the point to higher dimensions gives
where is the gradient and is the Hessian at . With a learning rate of , we find that
The three terms in the RHS expression mean, respectively,
- The original value of
- The expected improvement due to the slope
- The correction that should be applied to account for the function's curvature
When the last term , the Taylor series predicts that will always decrease as increases; in this case, smaller, heuristic choices of are used.
Otherwise, when the last term , the gradient descent step may move uphill, according to the approximation. Therefore, it suffices to solve for the optimal using this equation, which turns out to be
In the worst case, when aligns with the eigenvector of corresponding to the maximal eigenvalue , the optimal step size is
Therefore, the eigenvalues of the Hessian determine the scale of the learning rate!
Now, recall the second derivative test in two dimensions. Like how the first derivative test can be extended to higher dimensions with the gradient, so too can the second derivative test with the Hessian.
First, we compute the eigendecomposition of the Hessian matrix at some critical point . If the matrix...
- Is positive definite local minimum,
since the directional second derivative is positive in all directions. - Is negative definite local maximum,
since the directional second derivative is negative in all directions. - Has at least one positive eigenvalue and at least one negative eigenvalue saddle point,
since is a local maximum on one cross section of but a local minimum on another. - Otherwise (positive/negative semidefinite), inconclusive.
It may help to refer back to section 2.6 for some of the above definitions.
In higher dimensions, the existence of second derivatives in all directions means that the condition number of the Hessian, the measure of how different the second derivatives are from each other, matters. A poor condition number results in gradient descent performing poorly. See below for an example.
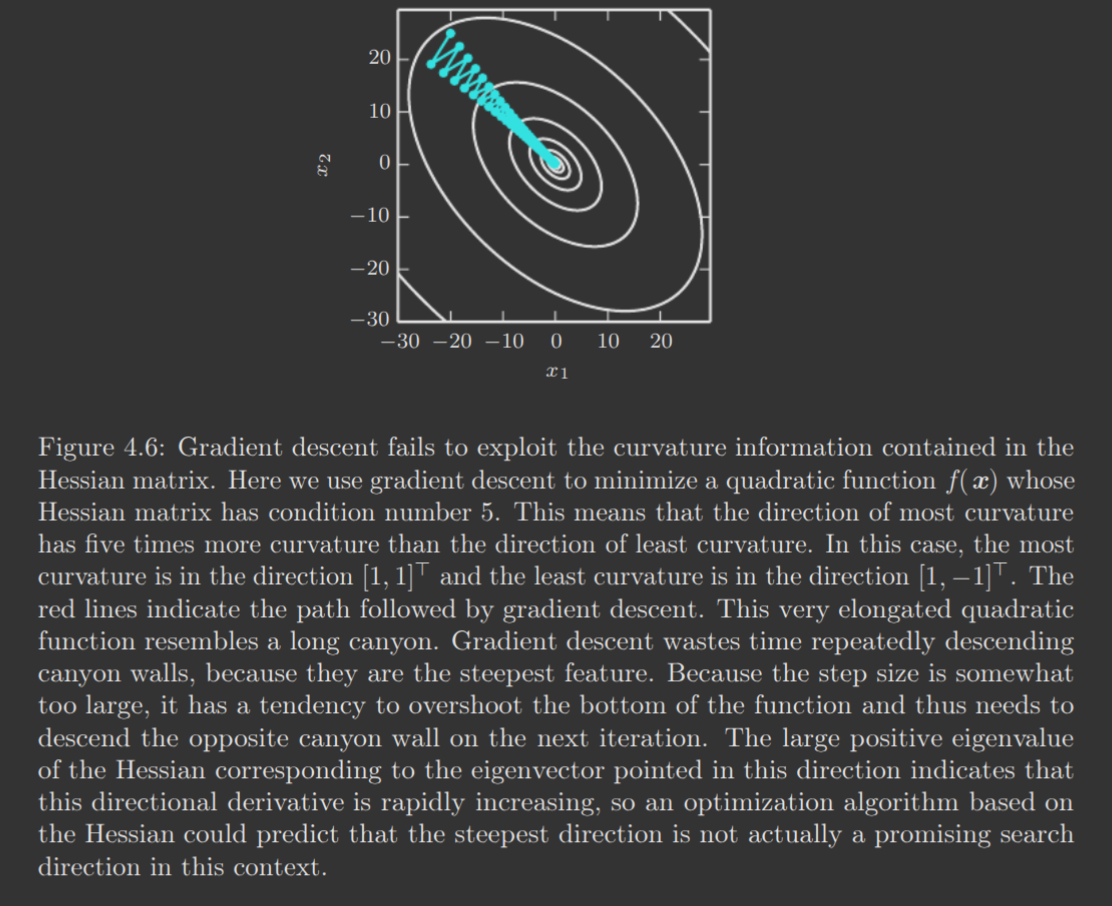
This issue can be resolved somewhat via techniques like Newton's method. Newton's method uses the second-order Taylor series expansion (previously shown) to approximate near a point and then solve directly for the critical point of the Taylor series.
Where and are again the Hessian and gradient evaluated at .
When is a positive definite quadratic function, Newton's method applies the above equation once to directly jump to the function minimum. When can be locally approximated as a positive definite quadratic, Newton's method applies the above equation iteratively.
Newton's method is faster than gradient descent, but fails if nearby a saddle point. It's only appropriate if the nearby critical point is a minimum (the Hessian is positive definite). Gradient descent is more robust in the presence of saddle points.
Optimization algorithms that use only the gradient (e.g. gradient descent) are first-order optimization algorithms. Those that also use the Hessian (e.g. Newton's method) are second-order.
Aside: Lipschitz Continuous
The algorithms discussed in this book are applicable to a wide variety of functions; but, as a direct consequence, provide few guarantees. In deep learning, some guarantees can be gained by considering only functions that are either Lipschitz continuous or have Lipschitz continuous derivatives.
A Lipschitz continuous function is a function whose rate of change is bounded by a Lipschitz constant .
This property enables quantifying the assumption that a small change in the input will have a small change in the output (by providing an upper bound on the possible change), while remaining a fairly weak constraint applicable to many optimization problems.
Aside: Convex Optimization
Convex optimization algorithms have much stronger restrictions—they apply only to convex functions, for which the Hessian is positive semidefinite everywhere. Such functions lack saddle points, and all of their local minima are global minima. Thus, these algorithms provide many more guarantees; however, many problems in deep learning cannot be solved by convex optimization.
4.4 Constrained Optimization
In some instances, it's desirable to minimize a function over a subset of the possible values of . This is constrained optimization, and all points are known as feasible points.
A simple approach is to simply use gradient descent and then project the result back into . Another approach is to design an unconstrained optimization problem whose solution may be transformed into a solution to the original; however, such transformations are difficult to invent and must be designed uniquely for each problem.
The Karsuh-Kuhn-Tucker (KKT) approach is a general solution to constrained optimization. It is, in essence, the generalization of Lagrange multipliers to multiple equality and inequality constraints.
Lagrange Multipliers
Lagrange multipliers is a method to find the minimum (or maximum) value of a function subject to the constraint , for some function . is usually interpreted as (or derived from) constraints. In essence, this solves constrained optimization with only equality constraints.
First, we define a function known as the Lagrangian. Note that , and its elements are termed Lagrange multipliers.
For our purposes, can be interpreted as equivalent to the dot product.
To find the minimum value of subject to the constraint, we must find all points such that they are critical points of the Lagrangian. In other words, all points such that
Computing the partial derivatives returns
implicitly evaluated at .
The first equation provides equations and the second provides equations (for each element of ). There are unknowns in the elements of and unknowns in the elements of . Thus, it suffices to solve the system of linear equations to produce the possible values of . Selecting the that produces the minimum value for thus solves the constrained optimization problem.
KKT Conditions
Now, we consider constrained optimization problems consisting of equality and inequality constraints.
Let be the cost function being minimized. Let there be functions and functions such that
The equations involving are the equality constraints, and those involving are the inequality constraints.
It's also possible to represent the constraints with two vector-to-vector functions and , as was done in the Lagrange multipliers section. The reason for the difference in notation is that the Lagrange multipliers section was written while referencing Wikipedia, as the book had no such section.
Next, we introduce the generalized Lagrangian.
Consider that, given and for any , then
This is because, any time the constraints are satisfied, we know
and any time it is violated
This is because, if for any , setting results in . Similar reasoning follows with , though in both directions ( and ).
Consequently, unconstrained optimization of this expression will always return a feasible point, as all infeasible points are suboptimal.
In reality, this involves solving a set of equations and inequalities in unknowns. See this blog postfor a more in-depth explanation, though this isn't particularly in scope.
Before we move on, we note some interesting properties of the inequality constraints. Some constraints are tight, i.e. , while others are not. Such tight constraints are denoted active. This is because the solution would remain at least a local solution if an inactive constraint were removed, as it is still a stationary/critical point.
For any inactive constraint, . Since is included in the expression, . (Otherwise, the enclosed expression would not be maximized). Intuitively, this is also because this constraint isn't actually affecting the solution locally.
This implies that
That symbol means component-wise multiplication—just think . Thus, this equation means , . In other words, for each constraint, either it is inactive, so that or active, so that .
The book states "for all , we know that at least one of the constraints and must be active at the solution." This took me so long to understand... because they reuse active here to mean whether or not this inequality is true. Why they chose to use "active" to mean this here after defining "active" previously regarding the constraints eludes me.
The KKT conditions provide a simple set of necessary, but not sufficient, conditions for a point to be optimal.
- The gradient of the generalized Lagrangian is at .
- All constraints on both and the KKT multipliers (the analogue of Lagrange multipliers for KKT) are satisfied.
- The inequality constraints exhibit complementary slackness: .