Chapter 6: Deep Feedforward Networks
Deep feedforward networks (a.k.a. feedforward neural networks, multilayer perceptrons/MLPs) are the foundational models of deep learning. The goal is approximating some function ; a feedforward network defines a mapping and learns the parameters that best approximate .
The models are termed feedforward because information flows from the input , through intermediate nodes/computations that define , and then to the output . There are no feedback connections—otherwise, they would be recurrent neural networks. We discuss these models further in Chapter 10.
Meanwhile, they are termed networks because they are represented by composing many different functions together in a DAG structure. The functions that are chained together form the layers of the model, and the number of layers gives the model's depth. The first layer is the input layer, and the last is the output layer. The layers between the two are the hidden layers.
Finally, they are termed neural because they are (loosely) inspired by neuroscience. Each hidden layer is typically vector-valued—the dimensionality determines the model's width. One may also think of each layer as consisting of many independent units or nodes that act in parallel.
6.1 Example: Learning XOR
First, we consider the simple task of learning the XOR function for a single bit.
Consider trying to perform linear regression to learn XOR. Minimizing the MSE will result in and for
In other words, the model just outputs , regardless of the input. This happens because the linear model is unable to learn the nonlinear behavior of the XOR function!
Now, we turn to a simple feedforward network with one hidden layer containing two hidden units; the hidden layer is represented by a vector of dimension , . The network can then be represented by the following equations.
and the complete model is, concisely, .
Of course, we cannot have both and be linear. Suppose and . Then , where . Clearly, then, the feedforward network can only represent linear functions.
Thus, we must use a nonlinear function. Most neural networks do so via the combination of an affine transformation and a nonlinear function known as the activation function.
provides the weights and provides the biases of this hidden layer, and these are, as described previously, learned parameters of this network. is the chosen activation function. Commonly, this is the rectified linear unit or ReLU.
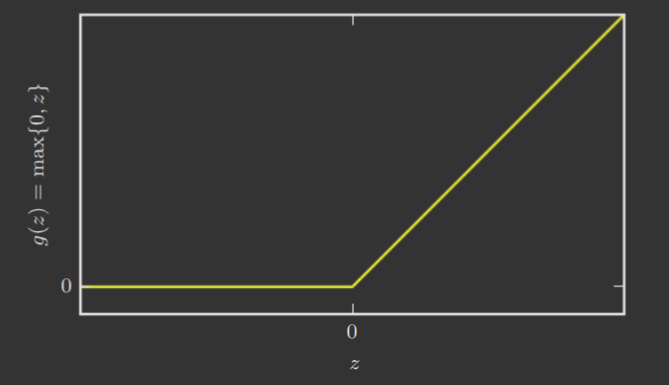
We discuss the motivation behind ReLU later.
Thus, our complete network is now
And one may note that the parameters
Correctly represents the XOR function! (Though, the model would not necessarily learn such clean parameters in real-world training or achieve perfect accuracy).
6.2 Gradient-Based Learning
The nonlinearity of neural networks, as one might expect, turns most useful loss functions non-convex. Hence, gradient-based optimizers are a necessity. This does mean there are no convergence guarantees; however, it is frequently possible to achieve sufficiently low error rates.
Cost Functions
The cost functions for neural networks are more or less the same as those for other parametric models.
Learning Maximum Likelihood
Most modern neural networks are trained using maximum likelihood, and thus the cost function is typically just negative log-likelihood or the cross entropy between the training data and model distribution.
Thus, for each model, there is no need to design a specific cost function; simply deriving it from maximum likelihood suffices!
This cost function is also useful because its desirable for the gradient of the cost function to avoid saturating (flattening/nearing zero). Many output units involve an exponential function that saturates with very negative arguments—the negative log-likelihood essentially counteracts the exponential. This interaction between cost function and choice of output unit is discussed further soon.
The cross-entropy cost function does not have a minimum value for many commonly used models, i.e. it approaches for some parameters. This is typically handled via regularization (as approaching probably implies overfitting).
Learning Conditional Statistics
Sometimes, we don't want to learn the full probability distribution , but rather just one conditional statistic of given , e.g. , the mean of .
First, consider that a (very powerful) neural network can represent any continuous, bounded function from a wide class of functions. This allows us to view the cost function as a functional: a mapping from the space of functions to . Thus, learning transforms from choosing parameters to choosing a function. Optimizing the cost function(al), then, requires calculus of variations—a technique we will not explain.
It does lead to the derivation of a couple interesting results.
Solving the optimization problem
yields . In other words, using MSE as the cost function produces a function that predicts the mean of given a value for .
Meanwhile, solving
yields a function predicting the median of given a value for . This cost function is commonly denoted the mean absolute error (MAE).
However, MSE and MAE are often poor cost functions for gradient-based optimization, as they induce some output units to saturate (and produce small gradients). Thus, even when estimating only statistics of given , cross entropy is still more popular.
Output Units
Linear for Gaussian
The simplest output unit is an affine transformation with zero nonlinearity. Given hidden features ,
Frequently, such output layers are used to produce the mean of a conditional Gaussian distribution
and minimizing cross entropy becomes equivalent to minimizing MSE.
Sigmoid for Bernoulli
As discussed previously, logistic regression applies a sigmoid to linear regression for a binary classification problem. A similar approach may be taken for neural networks.
Notably, choices such as
are, while valid, unsuitable for gradient descent because, if strays outside the unit interval, the model's gradient becomes .
We now consider the motivation behind using the sigmoid. Consider defining a probability distribution over using only a value . We let represent the likelihood of in an unnormalized probability distribution . Assuming the unnormalized log probabilities are linear in and , i.e. , we derive
In other words, normalizing the distribution to yield a Bernoulli distribution equates to a sigmoidal transformation of .
We assumed that unnormalized log probabilities are linear in and . Why?
The book does not detail the motivation behind this assumption, but here's my understanding of it. essentially is taken as a representation of the ratio between the probabilities of and . The log-probabilities are used instead because probabilities must be positive, logs turn ratios into differences. Then, can be explained by the observation that
In other words, the difference of the log-probabilities is equivalent to . Thus, the (unnormalized) binary distribution is parameterized by a single value, .
With the exp of the sigmoid, it's natural to use maximum likelihood learning. The loss function thus becomes
where you may recall as the softplus function. One may note that saturation of the loss function occurs only when the model has the right answer (either and is very positive, or and is very negative). On an incorrect answer, , and . The gradient, meanwhile, asymptotes to ( or , depending on the sign), meaning the gradient does not vanish when the model becomes more incorrect!
A loss function such as MSE, meanwhile, would saturate whenever saturates—as long as is very negative or very positive, the gradient vanishes.
Softmax for Multinoulli
We now extend binary classification to a general classification task over different categories. For this, we may use the extension of the sigmoid—the softmax.
where , where is defined analogously to the previous section. Again, one may visualize the softmax as interpreting quantities () as the differences between the log probabilities of the categories in . Also, note the log-likelihood of softmax.
Maximizing the log likelihood above encourages the correct to be increased (first term) while encouraging the sum of to be decreased (second term). One may also note that , due to the exponential. Therefore, the cost function strongly penalizes the most active incorrect prediction. Otherwise, if , i.e. the correct prediction is made, then the cost function is near zero.
Also, an interesting fact about the softmax is that it only responds to the difference between its inputs.
Therefore, the softmax is typically reformulated as
In order to avoid numbers with extremely large magnitudes in software.
Like the sigmoid, the softmax function saturates. In particular, it saturates to when the corresponding input is maximal () and . This represents the case where the model strongly classifies the input as category . And, like the sigmoid, this produces issues if the loss function does not compensate for the saturation.
The argument for the softmax function should also be of dimension , to represent the differences. However, it is often simpler to implement the overparametrized version of dimensions, in which an -dimensional vector is produced with the condition that .
Softmax induces some sort of competition between the input units, analogous to the lateral inhibition of neurons in the cortex.
Other Output Types
In general, maximum likelihood guides output layer design. One may imagine the neural network to represent some function whose output is some that provides the parameters for a distribution .
For instance, learning the variance of a distribution can be done by using a cost function , where . Thus, the variance is included as a parameter and the network learns the value of that enables the correct predictions of the distribution. In cases where is dependent on itself, it suffices to include variance as an output of the model, instead—this is known as a heteroscedastic model. Though, variance is typically represented via a diagonal precision matrix to make the gradient more well-behaved with maximum likelihood learning. (Otherwise, division is involved).
The division function becomes arbitrarily steep in gradient at zero. This causes instability. (Hence, variance is a bad choice for output).
The squaring function's gradient can vanish near zero. This can be difficult to learn. (Hence, standard deviation is a bad choice for output).
If desired, it's also possible to learn a covariance/precision matrix with richer structure than just diagonal. However, an appropriate parametrization must be chosen to ensure positive-definiteness of the predicted covariance matrix; this can be achieved by predicting some matrix where , where is an unconstrained square matrix.
For multimodal regression, i.e. predicting a distribution with multiple peaks, Gaussian mixture models are frequently used for the output. In short, the output consists of the probability, mean, and covariance matrix of each component Gaussian model.
6.3 Hidden Units
Now, we turn to the design of the hidden layers.
Throughout this section, we will encounter hidden units whose activation functions are not differentiable at all inputs. The popular ReLU, for instance, is not differentiable at . This may seem counterintuitive for a gradient-based learning algorithm; however, in practice, this is okay because training typically does not arrive at a local minimum of the cost function, but rather reaches a sufficiently small value. And, generally speaking, hidden units are non-differentiable at only a small subset of points, and even such points typically have defined left and right derivatives.
Unless otherwise specified, most hidden units vary only in their activation function , and can be defined as . Also, is typically applied element-wise.
Rectified Linear Units
As you may recall, rectified linear units are the default choice. The normal ReLU activation function is
ReLUs are easy to optimize because they are very similar to linear units. Whenever the unit is active, i.e. , the gradients remain large and consistent (derivative is ) and the second derivative is . Therefore, learning is easier for ReLU compared to other activation functions that introduce second-order effects.
With ReLU being applied to an affine transformation, i.e.
it's also typical to initialize the elements of to a small positive value to ensure that each ReLU is initially active for most inputs (and thus ensure nonzero gradients at the beginning of training).
As one might imagine, one major drawback of ReLUs is their inability to learn when inactive, i.e. . Thus, many ReLU generalizations attempt to address this issue, and are represented by the following function when .
where .
Absolute value rectification fixes to obtain . Leaky ReLU fixes to a small value, e.g. . Parametric ReLU or PReLU treats as learnable.
Maxout units are a different generalization that is not element-wise application. They separate into groups of values, and each maxout unit outputs the maximum element of its group. Formally,
where corresponds to (the indices of) the elements of group . This essentially represents learning a piecewise linear, convex function with pieces.
In essence, maxout units are essentially learning the activation function itself—with large enough , a maxout unit can approximate any convex function.
Maxout units may also be able to reduce the size of the next layer. They're additionally provided redundancy that resists catastrophic forgetting, where neural networks forget tasks they were previously trained on.
Maxout units are parametrized by weight vectors instead of just , so they typically require more regularization that ReLU.
In general, the ReLU and its generalizations are inspired by the principle that models are easier to optimize with linear-like behavior.
Logistic Sigmoid and Hyperbolic Tangent
Prior to the ReLU, most neural networks used either the logistic sigmoid activation function
or the hyperbolic tangent activation function
These activation functions are related, actually: .
However, their use in hidden units is now discouraged. This is primarily because these units saturate across most of their domain, translating to vanishing gradients during learning. Their continued use as output units is applicable to gradient-based learning because the appropriate cost function can counteract the saturation.
If a sigmoidal unit is desired or necessary, however, the hyperbolic tangent frequently performs better, as it resembles the identity function more closely since while . Thus, training a neural network like resembles training a linear model when activations are kept small.
Sigmoidal-like activation functions, despite their disuse in feedforward networks, are seen in other settings, such as recurrent networks.
Other Hidden Units
It's possible to have be simply the identity function (i.e. equivalent to no activation function). However, this results in some layers becoming entirely linear—this is generally only used to reduce the number of model parameters.
The softmax function may also be used as a sort of "switch"; this is typically applicable to architectures that specifically manipulate memory, which we discuss further in Chapter 10.
Some other common hidden types are
- Radial basis function: saturates to for most .
- Softplus: smooth ReLU, empirically ReLU is better
- Hard : .
6.4 Architecture Design
Architecture denotes the overall network structure. The main considerations for chain-based architectures is network depth and the width of each layer.
Universal Approximation Properties and Depth
The universal approximation theorem states that "a feedforward network with a linear output layer and at least one hidden layer with any 'squashing' activation function (such as the logistic sigmoid activation function) can approximate any Borel measurable function from one finite-dimensional space to another with any desired non-zero amount of error, provided that the network is given enough hidden units." A Borel measurable function, for our purposes, describes a continuous function on a closed and bounded subset of .
TL;DR: sufficiently large feedforward networks can represent most useful functions.
However, there is no guarantee that the learning algorithm will choose the correct parameters. Moreover, a single layer network may require an exponentially large width for the hidden layer.
Thus, it's useful to extend the number of hidden layers to reduce the number of units necessary to learn the desired function. In fact, many families of functions can only be efficiently (non-exponentially) approximated with a depth , for some .
An intuitive, geometric explanation for this exponential advantage of deeper networks arises from absolute value rectification, in which each additional hidden layer essentially "folds" the input space, allowing the representation of essentially linear regions/pieces of a piecewise function, where is the depth.
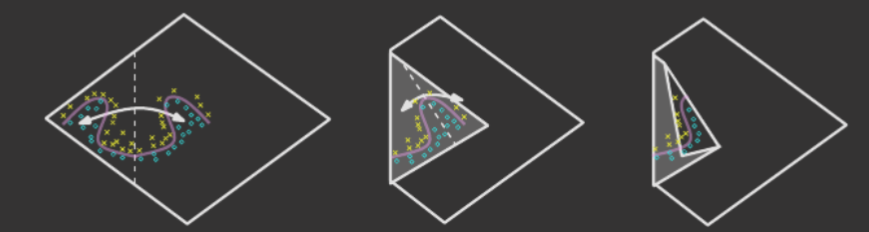
More precisely, the number of linear regions represented by a deep rectifier network with inputs, depth , and units per hidden layer is
Generally speaking, though, extending the depth of a model is frequently a useful prior.
Other Architectural Considerations
There are many special architectural designs for specific tasks. We leave such details for later, when we discuss such architectures.
6.5 Back-Propagation and Other Differentiation Algorithms
The evaluation of an input by a feedforward network to produce an output is known as forward propagation. During training, this produces a scalar cost . The back-propagation or backprop algorithm propagates this value backwards through the network, computing the gradient used for the actual descent algorithm.
Back-propagation is frequently misunderstood to mean the whole learning algorithm for feedforward networks. This is inaccurate; it merely describes the algorithm used to compute the gradients of the parameters, which is then used for an algorithm like stochastic gradient descent.
Formally, backprop computes the gradient for some function , where is a set of variables whose derivatives are desired and is an additional set of variables whose derivatives are not desired. For machine learning, this is typically .
Computational Graphs
Computational graphs help us more formally visualize the structure of operations like back-propagation.
- Each node in the graph corresponds to a variable.
- An operation is a simple function of one or more variables that returns a single output variable.
- If is computed by applying an operation to a variable , a directed edge is drawn from .
Chain Rule of Calculus
We briefly review chain rule.
For scalars, with and ,
For vectors, with , , , and ,
For tensors, where the variables and functions are defined analogously,
Recursive Chain Rule Backprop
I won't go into the mathematics behind this. But, I think it should be pretty intuitive how this works.
The more critical realization here is the use of memoization to store computed derivatives across propagation; otherwise, the algorithm would experience an exponential explosion.
Symbol-to-Symbol Derivatives
Algebraic expressions and computational graphs operate on symbols, and are thus known as symbolic representations. This motivates two different approaches to backprop:
- Symbol-to-number: given a computational graph and the numerical values of the inputs, return a set of numerical values describing the gradients. (Used by PyTorch)
- Symbol-to-symbol: given a computational graph, add additional nodes that provide a symbolic description of the desired derivatives, and then run computations on the graph later given the numerical values of he inputs. (Used by TensorFlow). This approach has the advantage of being able to differentiate the derivatives and produce higher derivatives. A diagram of an example transformation is shown below.
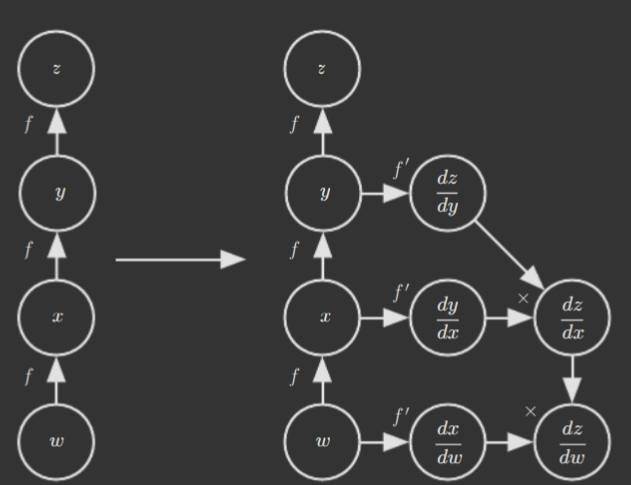
Yes, that's correct. However, the symbol-to-symbol approach can be understood as a more general version that explicitly exposes the computational graph. The symbol-to-number approach does not, and thus loses the capability to compute higher derivatives.
MLP Back-Propagation
I think MLP backprop can be sufficiently understood via a single diagram displaying backprop of a single layer network. No need to understand it in detail; just note the computational graph displays precisely the operations of the MLP and the gradient is computed on this graph starting from the loss function and proceeding backward, in a postorder DFS manner. (Think reverse topological sort, since the computational graph is a DAG).
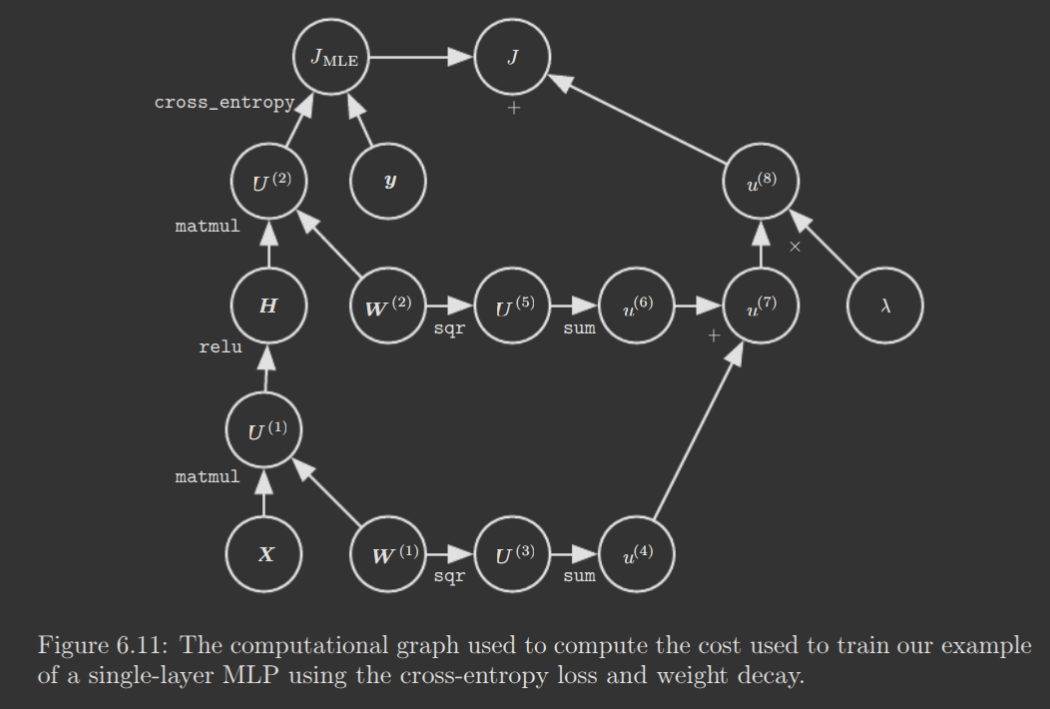
Complications
There are some real-world issues that increase the complexity of actual backprop implementations. We won't discuss them in detail; just know they do exist!
Differentiation outside Deep Learning
The field of automatic differentiation discusses, well, automatic, algorithmic computation of derivatives. Backpropagation is a member of a broader class of techniques in this field known as reverse mode accumulation—as one might imagine, this describes the backwards, propagative calculation of derivatives through a computational graph such as the one produced by an MLP. In general, though, determining the optimal sequence of operations to compute the gradient is an -Complete problem. There do, however, exist some optimizations implemented in modern deep learning software.
Forward mode accumulation is also potentially preferable when the number of outputs of the graph is larger than the number of inputs; it is to reverse mode as matrix left-multiplication is to matrix right-multiplication. Typically, though, machine learning deals with problems with many input features and few output features. This has seen some consideration for recurrent networks, though (which frequently have many output features).
Higher Order Derivatives
As aforementioned, some symbol-to-symbol software libraries can compute higher order derivatives. However, this has some issues. For second derivatives, for instance, we're interested in the properties of the Hessian matrix. For a function , though, the Hessian matrix is of dimensions —when is in the billions, this quickly becomes intractable.
Instead, deep learning typically leverage Krylov methods, a set of iterative techniques that approximate the properties of the Hessian without explicitly computing it.