Chapter 7: Regularization for Deep Learning
As aforementioned, regularization is the study of how to train models that generalize well to unseen inputs. For deep learning, most regularization strategies are based on regularizing estimators, typically by sacrificing bias (increasing bias) to reduce variance. In other words, preventing overfitting.
7.1 Parameter Norm Penalties
The simplest form of regularization is a parameter norm penalty , added to the objective function to produce the regularized objective function .
Note that is a hyperparameter that weights the contribution of the penalty term . Larger induces grater regularization. This section, we'll discuss the choice of the parameter norm and its effects.
Typically, the parameter norm penalty is only chosen to penalize the weights at each layer, and not the biases. This is because regularizing the biases can cause significant underfitting, and leaving them unregularized does not induce much variance since they affect only a single variable (while weights specify interaction between variables). Thus, commonly equates to .
Sometimes, it may be desirable to use different for each layer. However, this may make hyperparameter selection more expensive/difficult, so it's reasonable to use the same for all layers.
Regularization
We begin with the simplest parameter norm penalty: or weight decay. It's also known as ridge regression or Tikhonov regularization, and involves adding a regularization term .
The new cost function gradient is then
And the gradient step is
In other words, the weight decay term induces the gradient descent to shrink the previous weight vector by a constant factor on each step. So, what happens across the entirety of training?
We first simply analysis by making a quadratic approximation (Taylor series) of the (original) objective function in the neighborhood of the cost-minimizing weights:
where is the Hessian matrix of with respect to evaluated at , the cost-minimizing weights.
is the minimizing value, so the gradient is . Additionally, this implies is positive semidefinite.
Naturally, the minimum of occurs when its gradient
is .
Now, consider adding the weight decay back. Now, the gradient becomes
where represents the minimum of the regularized version of the approximation . Equating to and solving for , we derive
Note that . But what about when grows?
is real and symmetric, therefore we can eigendecompose it. This allows deriving
In words, this means that weight decay effectively rescales along the axes defined by the eigenvectors of . Specifically, the component of aligned with eigenvector of is rescaled by a factor of . See section 2.7 if you're confused.
Thus, along directions where , the regularization has minimal effect. In contrast, if , these components will be shrunk significantly. A visualization is displayed below.

In other words, only directions that contribute substantially to reducing the cost function are preserved.
One can interpret its effects, for instance, on linear regression. Applying regularization changes the solution to
Note that the covariance matrix is . Thus, regularization, adding to each element of the diagonal, appears to induce additional variance in the input (recall that ) and thus shrink the weights for features whose covariance with the output target is comparatively small.
Regularization
Formally,
and
with gradient
Notably, the contribution of the regularization term no longer scales according to ; instead, it is either or . This actually means that there are no clean algebraic solutions to quadratic approximations of , like there were for regularization.
We can still interpret the quadratic approximation, however. Again,
Given our limitations, we will assume the Hessian is diagonal with all positive elements. This holds if the data has been preprocessed to remove correlation between input features (e.g. preprocess with PCA). Thus, the approximation of our regularized objective function becomes
The analytical solution is
WLOG, let for all . Consider if
- . Then, the optimal value of under regularization is .
- . Then, the regularization simply shifts it towards zero by .
The behavior is similar with for .
The notable aspect of regularization, as hinted above, is that it produces a sparse solution, as it zeroes some parameters. ( regularization does not introduce sparsity; rescaling never zeroes a component). This is critical for tasks like feature selection, i.e. selecting a subset of the available features to be used as input. This is well known as LASSO (Least Absolute Shrinkage and Selection Operator) in the context of linear models.
Remember MAP Bayesian inference from section 5.6? regularization may be represented by MAP with a prior of an isotropic Laplace distribution over .
7.2 Norm Penalties as Constrained Optimization
We previously alluded to the relation between norm penalties and the generalized Lagrange function used for constrained optimization. We now discuss this in more detail.
For instance, if we wanted to constraint , we construct a generalized Lagrangian
With solution
Though, as mentioned in section 4.4, solving the problem requires learning/solving for both and . Theoretically, it's possible to solve for the value of that corresponds to an ; however, it varies depending on the objective function itself. Instead, we use as a hyperparameter, and manually control it to roughly adjust the constraint region. Again, larger strengthens the constraints, while smaller weakens them.
Occasionally, however, explicit constraints are desired, i.e. we want to limit by a precisely chosen value of . Rather than solving for the corresponding , this can be done by using SGD and then projecting back to the nearest constraint-satisfying point. This explicit constraints and reprojection method is, at times, useful:
- Using penalties can result in non-convex optimization algorithms getting stuck in local minima
- Optimization algorithms with high learning rates can encounter positive feedback loops, which are unregulated without explicit constraints.
7.3 Regularization and Under-Constrained Problems
Regularization may even be necessary for a machine learning problem to be properly defined.
For instance, many linear models depend on inverting , which may not be invertible. Thus, many use instead, which is always invertible.
For underdetermined problems, learning algorithms may never converge; regularization can ensure convergence eventually occurs.
Recall that it may be defined as
In fact, you might not recognize this as performing linear regression with weight decay! Thus, the pseudoinverse stabilizes underdetermined problems with regularization.
7.4 Dataset Augmentation
In practice, data is limited. One solution for this is the creation of fake data. Depending on the task, this may be straightforward!
Small changes like translation, saturation, rotation, etc. of existing examples can produce new examples.
Injecting noise into the input of a neural network is also data augmentation. Many tasks should be possible to solve even with small perturbations to the input. Noise injection also works for hidden units; dropout, which we discuss soon, can be interpreted as constructing new inputs by multiplying by noise.
7.5 Noise Robustness
As aforementioned, it's desirable for a model to be resistant to noise in the inputs. Beyond just injecting noise into the inputs, it's possible to achieve this by injecting noise into the weights. Adding small perturbations during training actually encourages parameters to tend to regions of parameter space that are flat, i.e. insensitive to small variations of weights. Refer to the book for the math behind this.
It's also possible to inject noise into the output targets. This is desirable because datasets frequently have some mistakes in the outputs. Label smoothing is one technique that regularizes a model with a softmax of different values by replacing hard classification targets with targets of and , where we are assuming each category label is correct with probability . This also helps encourage convergence for maximum likelihood learning.
7.6 Semi-Supervised Learning
In semi-supervised learning, we use both unlabeled examples from and labeled examples from to estimate . The motivation is that the unsupervised part of the learning can hint towards how to group examples in representation space. In essence, you can think of the unsupervised part as performing the clustering, and the supervised part actually labeling the clusters.
It's not necessary to separate the unsupervised and supervised components, however. It's possible to construct models in which a generative/unsupervised model, either or shares parameters with a discriminative/supervised model of . One may then minimize some function of the supervised criterion and the unsupervised/generative criterion. In essence, the generative criterion expresses a prior about the supervised problem's solution; that the structures are connected in a way that may be captured via shared parametrization.
7.7 Multi-Task Learning
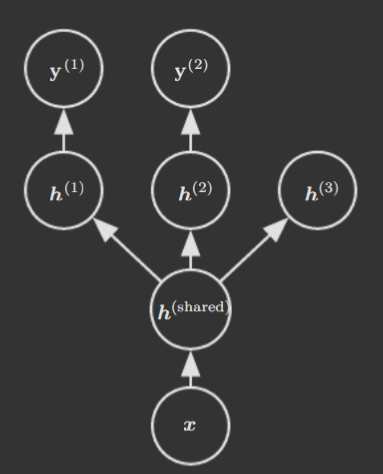
Multi-task learning involves using examples from several different tasks to improve generalization. A very common form of multi-task learning involves the different tasks sharing the same input and some portion of the hidden layers intended to capture some common factors—generic parameters. The other hidden layers (and output layer) are the task-specific parameters. Below shows an example architecture.
7.8 Early Stopping
When training large models with sufficient representational capacity to overfit, training error will typically continuously decrease, but validation error will begin increasing after enough iterations. Therefore, it's frequently (really, almost always) desirable to stop the gradient descent algorithm at some point, when the training error has become sufficiently small, to prevent overfitting.
The most common method for this is recording the validation error every time we see an improvement, and returning to the parameter values at the point in which the validation error is minimized. This is known as early stopping, and can be interpreted as an efficient hyperparameter selection algorithm where we treat the number of training steps as a hyperparameter.
Early stopping is popular for a couple reasons.
- No trial and error for number of training steps
- Easy to add without harming learning dynamics
- It acts as a regularizer
There are a couple considerations with early stopping, though. Early stopping requires a validation set; a common strategy is to perform two sets of training—one without the validation set that uses early stopping, and then one with all training data (i.e. validation set is now training data). There are two options for the second training procedure.
- Reset parameters, and retrain for the same number of steps as the first training, which early stopping determined to be optimal.
- Keep parameters, and continue training, but with all data. This avoids the cost of retraining, but is not well-behaved without a good guide for when to stop. Practically, the algorithm stops when the average loss function on the validation set falls below the loss at the end of early stopping.
Previously, we discussed how early stopping acts as a regularizer. Now, we formalize this notion, and show that early stopping essentially equates to regularization (for a simple linear model with quadratic error function trained by gradient descent).
As before, we make a quadratic approximation of the cost function in the neighborhood of the optimal weights .
And compute the gradient
Now, we consider how the parameters change during gradient descent. WLOG, assume .
Rewriting with 's eigendecomposition and simplifying returns (plus some small assumptions)
While doing some rearrangement in the equation from [[7. Regularization for Deep Learning# Regularization|section 7.1]] gives
Therefore, if hyperparameters are chosen such that
regularization and early stopping are equivalent! In fact, one can conclude that , provided the eigenvalues are sufficiently small.
Intuitively, this is because training learns the directions of high curvature first, and early stopping halts training before the model learns directions of low curvature. Of course, the equivalence only holds for a quadratic approximation of the objective function; however, the primary idea of this relationship generally holds.
7.9 Parameter Tying and Sharing
Frequently, we may want to express a prior that two models should be similar to each other. For instance, two models performing the same classification task with slightly different input distributions.
For this purpose, we can add a parameter norm penalty that ties the models' parameters to each other
for models and . However, a more popular approach is actually to use constraints that force sets of parameters to be equal—this is parameter sharing. The primary advantage of this approach is that it reduces memory footprint—only a subset of the parameters, i.e. the unique shared set, need to be stored in memory.
Parameter sharing has been used to great effect in CNNs. With many image-related tasks requiring invariance to translation, it's desirable to share the same parameters within the model, between different locations in the image, essentially. We discuss this in detail in Chapter 9.
7.10 Sparse Representations
Recall the regularization penalty, and how it encourages a sparse parameterization, i.e. encourages many weights to be . Sparseness can also be encouraged in the representation of the data, i.e. in the hidden layers (e.g. a hidden layer with only a few active units). This can be implemented with a norm penalty on the representation:
where represents a hidden layer(s). For sparsity, an penalty is typically useful; though other sparsity-encouraging penalties exist too.
Other approaches place a hard constraint on activation values instead. Orthogonal matching pursuit, for instance, seeks a representation such that
where denotes the number of nonzero entries of , i.e. it limits the number of active units in the layer to . The problem is tractable when is constrained to be orthogonal, hence the nomenclature, and is often termed "OMP-."
7.11 Bagging and Other Ensemble Methods
Bagging, or bootstrap aggregating, separately trains different models and then asks models to vote on test examples. It's an instance of model averaging, a subset of ensemble methods which leverage multiple different models for output.
The motivation for model averaging is that, if the models make errors independently, the errors will be reduced. In fact, for a set of regression models, expected squared error decreases linearly in , given fully uncorrelated errors between models.
Note that, typically, in order to construct separate models, the dataset is preprocessed to create different datasets by sampling with replacement from the original dataset. The datasets are all the same size, but with high probability are missing examples from the original dataset. Moreover, with the inherent stochasticity in model training (random initialization, random minibatches, etc.), we may expect sufficient distinctions between models to observe benefits from ensemble learning.
7.12 Dropout
Dropout is a powerful, popular method of regularization that provides, effectively, an efficient approximation of bagging.
Dropout essentially models an exponentially large set of models by randomly removing, or dropping, non-output units from an underlying base networks. In most networks, this can be done by multiplying a unit's output value by zero. This process is repeated on the base network for every minibatch during training (model is reset back to base model between iterations), and each unit has an independent probability , a hyperparameter, of being dropped. Thus, every training example sees and trains a different model, effectively; except these models share many (but not all) parameters due to being selected from the same underlying model.
Formally, suppose a binary mask vector , randomly selected, specifies the units to include (from the set of input/hidden units) and denotes the cost function. Dropout training minimizes . This expectation contains exponentially many terms; however, sampling values of provides an unbiased estimate of the gradient.
The critical idea of dropout, when compared to bagging, is its parameter sharing, which enables representing exponentially many models with a tractable memory size. Moreover, in dropout, only a small fraction of the possible sub-networks are trained—each for a single step. Yet, the parameter sharing allows for reasonably approximate gradient descent.
At test time, a bagged ensemble accumulates votes from all member models; this is known as inference.
In dropout, each sub-model defined by mask vector defines a probability distribution . We can still use the arithmetic mean:
where is the probability distribution from which is sampled from during training. However, this is intractable to evaluate—there are exponentially many .
We could approximate dropout inference by averaging the output of a few randomly sampled masks. But, there's still a better approach, which enables a good approximation of the ensemble prediction using only one forward propagation.
By replacing the arithmetic mean with the geometric mean, i.e.
where is the number of units that may be dropped (i.e. dimension of ). Note that, for simplicity, we must guarantee that no sub-model assigns probability to an event—otherwise, we have a high risk of the ensemble probability becoming .
Also, note that the above distribution is not normalized (hence the ~ above ), so the ensemble evaluation is really
Nevertheless, the key insight here is that we can approximate by evaluating using just the model with all units, with a slight modification—all weights exiting unit are multiplied by the probability of including unit . This is known as the weight scaling inference rule.
For networks without nonlinear units, the application of this rule perfectly models . Otherwise, however, it is an approximation.
So, why is dropout so popular?
- Empirically, it performs better than other common regularizers
- It is computationally very cheap
- It works for nearly any model with a distributed representation
- It works well with SGD
It does have a couple drawbacks, though.
- It reduces the model capacity, and often necessitates substantially increasing model size.
- With extremely small datasets, it's less effective.
Interestingly, stochasticity is unnecessary for dropout—it's just a means of approximating the bagging ensemble method. A variant known as fast dropout reduces stochasticity significantly to achieve faster convergence.
An additional insight into dropout's benefits is that, not only is it training an ensemble of models, but it is also forcing units to essentially "adapt" when used in a variety of different networks. This regularizes hidden units to be a feature that performs well/contributes in many contexts, thus decreasing generalization error.
Dropout is also a form of noise injection, in the sense that it randomly erases some hidden units or features from the model, forcing the model to redundantly encode some information. (This process is also a multiplicative injection of noise, as alluded to previously). Thus, dropout improves noise robustness.
7.13 Adversarial Training
An adversarial example is an example extremely close to a real example, according to a human observer, that produces very different predictions from the model. This is, naturally, undesirable; however, training models to avoid misclassifying adversarial examples is beyond this chapter's scope (though this technique does somewhat help). Instead, we consider adversarial training: a regularization technique that trains models on adversarially perturbed examples.
One important observation is that excessive linearity is a common cause of adversarial examples. Adversarial training serves to discourage highly sensitive, locally linear behavior, and essentially expresses a local constancy prior.
Adversarial examples can also provide a method for semi-supervised learning. Given an unlabeled input , we compute the model's predicted label . Then, we search for an adversarial example that is adversarial to the model's prediction . Since the model's label, not the true label, was used, this is known as a virtual adversarial example. By using this in adversarial training, this encourages robustness to small changes to inputs—formally, robustness to small translations along the manifold of the unlabeled data, given that different classes usually lie on separate, disconnected manifolds.
7.14 Tangent Distance, Tangent Prop, and Manifold Tangent Classifier
Recall the manifold hypothesis from Chapter 5, which suggests that, for most real-world data, there exists a low dimensional embedding within the greater, high dimensional space.
The tangent distance algorithm was an earlier invention to make use of this hypothesis; it's a non-parametric nearest neighbor algorithm with one difference: the distance metric is not Euclidean distance, but instead one derived from knowledge of the low dimensional manifolds. In essence, becomes , i.e. the shortest distance between points in manifolds and , where and .
Naively computing is intractable; however, a cheap alternative is to approximate with the tangent plane at and measure the distance between the two tangents. However, this requires manually specifying/calculating the tangent vectors for each .
In a similar vein, the tangent prop algorithm trains a neural network classifier with an extra penalty intended to make the output locally invariant to known factors of variation, i.e. movement along the example's manifold. This is achieved by encouraging to be orthogonal to the known manifold tangent vectors at , or encouraging the directional derivative of at in the directions to be small. The corresponding regularization penalty would be
As with tangent distance, though, the tangent vectors must be derived a priori.
Tangent propagation also has several flaws when compared to similar methods like data augmentation.
- It only regularizes infinitesimal perturbations.
- It's not suitable for ReLUs.
Double backprop is a technique that regularizes the Jacobian to be small. Both it and adversarial training encourage model invariance to certain directions of transformation, like tangent prop. Notably, just how tangent prop is the infinitesimal version of data augmentation, double backprop is the analogue for adversarial training.
Finally, in 2011, the manifold tangent classifier was created, which eliminates the most glaring issue of tangent propagation—knowing the tangent vectors before training. It makes use of autoencoders, a model structure discussed in Chapter 14, to approximately learn manifold tangent vectors.